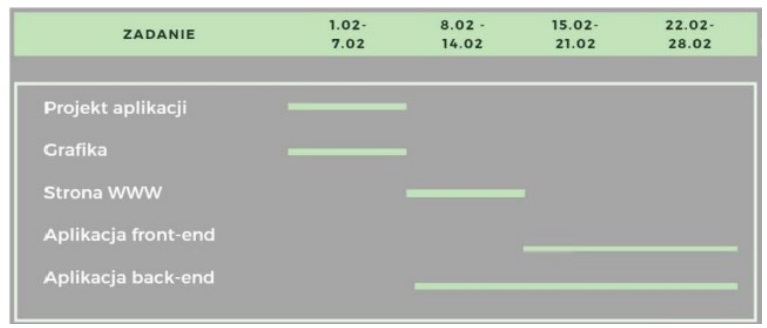
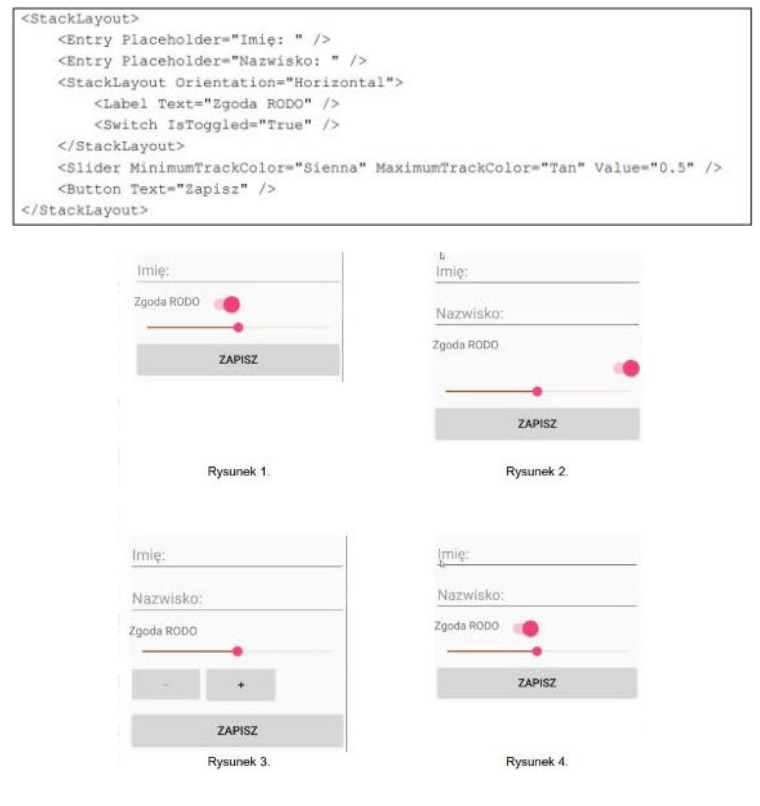
Pytanie 1
Dziedziczenie jest używane, gdy zachodzi potrzeba
A. sformułowania klasy bardziej szczegółowej niż już stworzona
B. określenia zasięgu dostępności metod i pól danej klasy
C. asynchronicznej realizacji długotrwałych zadań
D. wykorzystania stałych wartości, niezmieniających się w trakcie działania aplikacji
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Dziedziczenie to naprawdę jeden z kluczowych fundamentów programowania obiektowego. Chodzi tu o możliwość stworzenia nowej klasy (tzw. klasy pochodnej), która rozszerza lub precyzuje działanie już istniejącej klasy bazowej. Dzięki temu nie trzeba pisać wszystkiego od nowa – można po prostu przejąć cechy i zachowania ogólnej klasy, a potem dołożyć własne, bardziej szczegółowe funkcjonalności. Przykład? Klasa "Pojazd" może być ogólna, a potem robisz z niej "Samochód", "Rower" czy "Motocykl". Każda z tych klas dziedziczy podstawowe właściwości pojazdu (jak np. liczba kół), ale może mieć swoje dodatkowe pole czy metodę. W praktyce to pozwala na bardzo elastyczne i czytelne projektowanie kodu, no i łatwiejsze zarządzanie nim na dłuższą metę. Według większości standardów branżowych, np. w językach Java, C# czy C++, dziedziczenie jest zalecane właśnie wtedy, gdy chcesz odwzorować relację „jest rodzajem” (is-a). Z mojego doświadczenia, używanie dziedziczenia według tej zasady pozwala uniknąć wielu problemów z powielaniem kodu i z czasem naprawdę oszczędza mnóstwo roboty. Warto pamiętać, że nie wszystko należy dziedziczyć na siłę – czasem lepiej postawić na kompozycję, ale jeśli faktycznie potrzebujesz klasy bardziej szczegółowej, to dziedziczenie to chyba najlepszy wybór.
Dziedziczenie to naprawdę jeden z kluczowych fundamentów programowania obiektowego. Chodzi tu o możliwość stworzenia nowej klasy (tzw. klasy pochodnej), która rozszerza lub precyzuje działanie już istniejącej klasy bazowej. Dzięki temu nie trzeba pisać wszystkiego od nowa – można po prostu przejąć cechy i zachowania ogólnej klasy, a potem dołożyć własne, bardziej szczegółowe funkcjonalności. Przykład? Klasa "Pojazd" może być ogólna, a potem robisz z niej "Samochód", "Rower" czy "Motocykl". Każda z tych klas dziedziczy podstawowe właściwości pojazdu (jak np. liczba kół), ale może mieć swoje dodatkowe pole czy metodę. W praktyce to pozwala na bardzo elastyczne i czytelne projektowanie kodu, no i łatwiejsze zarządzanie nim na dłuższą metę. Według większości standardów branżowych, np. w językach Java, C# czy C++, dziedziczenie jest zalecane właśnie wtedy, gdy chcesz odwzorować relację „jest rodzajem” (is-a). Z mojego doświadczenia, używanie dziedziczenia według tej zasady pozwala uniknąć wielu problemów z powielaniem kodu i z czasem naprawdę oszczędza mnóstwo roboty. Warto pamiętać, że nie wszystko należy dziedziczyć na siłę – czasem lepiej postawić na kompozycję, ale jeśli faktycznie potrzebujesz klasy bardziej szczegółowej, to dziedziczenie to chyba najlepszy wybór.