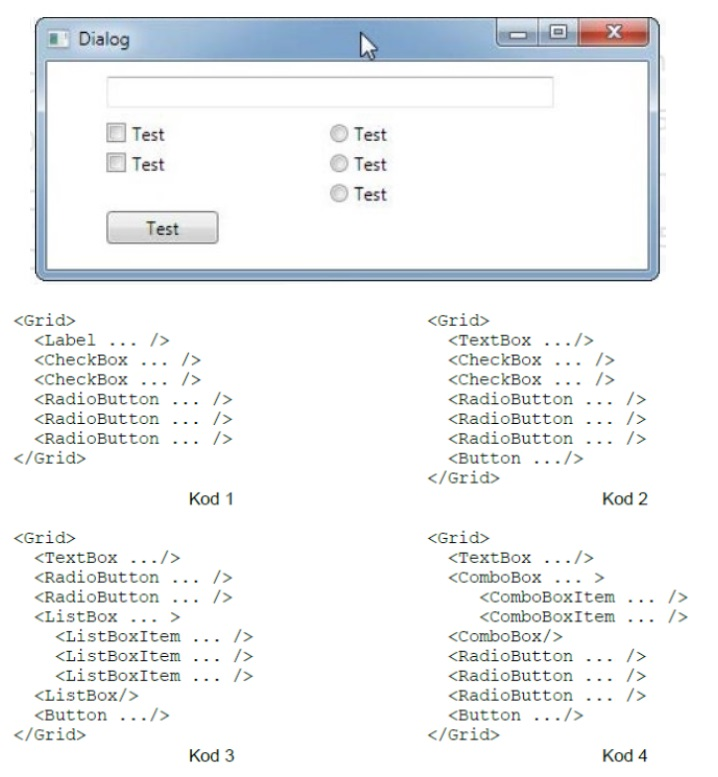
Pytanie 1
Co to jest API w kontekście programowania?
A. System zarządzania relacyjnymi bazami danych
B. Metoda kompresji danych w aplikacjach webowych
C. Interfejs programistyczny aplikacji, który definiuje sposób komunikacji między różnymi komponentami oprogramowania
D. Narzędzie do testowania interfejsu użytkownika aplikacji
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
API, czyli Interfejs Programistyczny Aplikacji, to zestaw reguł i protokołów, które umożliwiają różnym komponentom oprogramowania komunikację ze sobą. W praktyce API działa jako most między różnymi systemami, pozwalając na wymianę danych oraz funkcji. Na przykład, API może być wykorzystywane do integracji z zewnętrznymi serwisami, takimi jak systemy płatności, co pozwala na łatwe wdrożenie funkcji zakupów online w aplikacji. Stosowanie API zgodnie z zasadami RESTful czy GraphQL jest powszechną praktyką, ponieważ ułatwia rozwój i utrzymanie aplikacji, umożliwiając tworzenie skalowalnych rozwiązań. Co więcej, dobrze zdefiniowane API zwiększa bezpieczeństwo aplikacji, ograniczając bezpośredni dostęp do wewnętrznych mechanizmów oraz danych. Firmy często tworzą dokumentację API, aby programiści mogli szybko zrozumieć, jak z niego korzystać, co jest zgodne z zasadami dobrych praktyk w branży programistycznej.
API, czyli Interfejs Programistyczny Aplikacji, to zestaw reguł i protokołów, które umożliwiają różnym komponentom oprogramowania komunikację ze sobą. W praktyce API działa jako most między różnymi systemami, pozwalając na wymianę danych oraz funkcji. Na przykład, API może być wykorzystywane do integracji z zewnętrznymi serwisami, takimi jak systemy płatności, co pozwala na łatwe wdrożenie funkcji zakupów online w aplikacji. Stosowanie API zgodnie z zasadami RESTful czy GraphQL jest powszechną praktyką, ponieważ ułatwia rozwój i utrzymanie aplikacji, umożliwiając tworzenie skalowalnych rozwiązań. Co więcej, dobrze zdefiniowane API zwiększa bezpieczeństwo aplikacji, ograniczając bezpośredni dostęp do wewnętrznych mechanizmów oraz danych. Firmy często tworzą dokumentację API, aby programiści mogli szybko zrozumieć, jak z niego korzystać, co jest zgodne z zasadami dobrych praktyk w branży programistycznej.