Pytanie 1
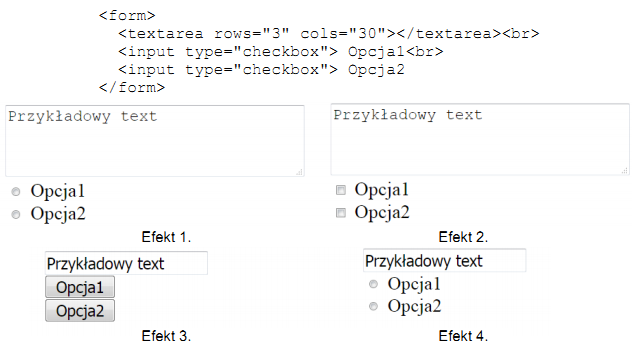
Zaprezentowano rezultat zastosowania CSS oraz odpowiadający mu kod HTML. W jaki sposób trzeba zdefiniować styl, aby uzyskać takie formatowanie?

A. p.first-letter { font-size: 400%; color: blue; }
B. p::first-letter { font-size: 400%; color: blue; }
C. #first-letter { font-size: 400%; color: blue; }
D. .first-letter { font-size: 400%; color: blue; }
Wybór innych odpowiedzi niż p::first-letter jest niepoprawny z kilku powodów. Po pierwsze, użycie samego .first-letter odnosi się do elementu z klasą first-letter, co oznaczałoby, że kod HTML musiałby mieć element z przypisaną tą klasą, co nie jest zgodne z przedstawionym kodem. Podobnie, #first-letter wskazywałaby na element z identyfikatorem first-letter, co również wymagałoby odpowiedniej struktury w kodzie HTML. Obie te opcje ignorują fakt, że mamy do czynienia z pseudo-elementem, który specyficznie stylizuje pierwszą literę danego bloku tekstu. Z kolei zapis p.first-letter byłby próbą stylizacji elementów p z klasą first-letter, co jest błędnym zastosowaniem w kontekście potrzeby modyfikacji pierwszej litery. Kluczowym problemem w powyższych odpowiedziach jest niewłaściwe zrozumienie, jak działają pseudo-elementy oraz jak są używane w praktyce. Pseudo-elementy takie jak ::first-letter są bezpośrednio zdefiniowane w specyfikacji CSS i pozwalają na precyzyjne stylizowanie części elementów, co jest istotne w kontekście semantycznego i czystego kodu HTML. W świecie nowoczesnych technologii webowych, zrozumienie, kiedy i jak stosować pseudo-elementy, jest kluczowe dla tworzenia efektywnych i zachwycających wzrok projektów.