Pytanie 1
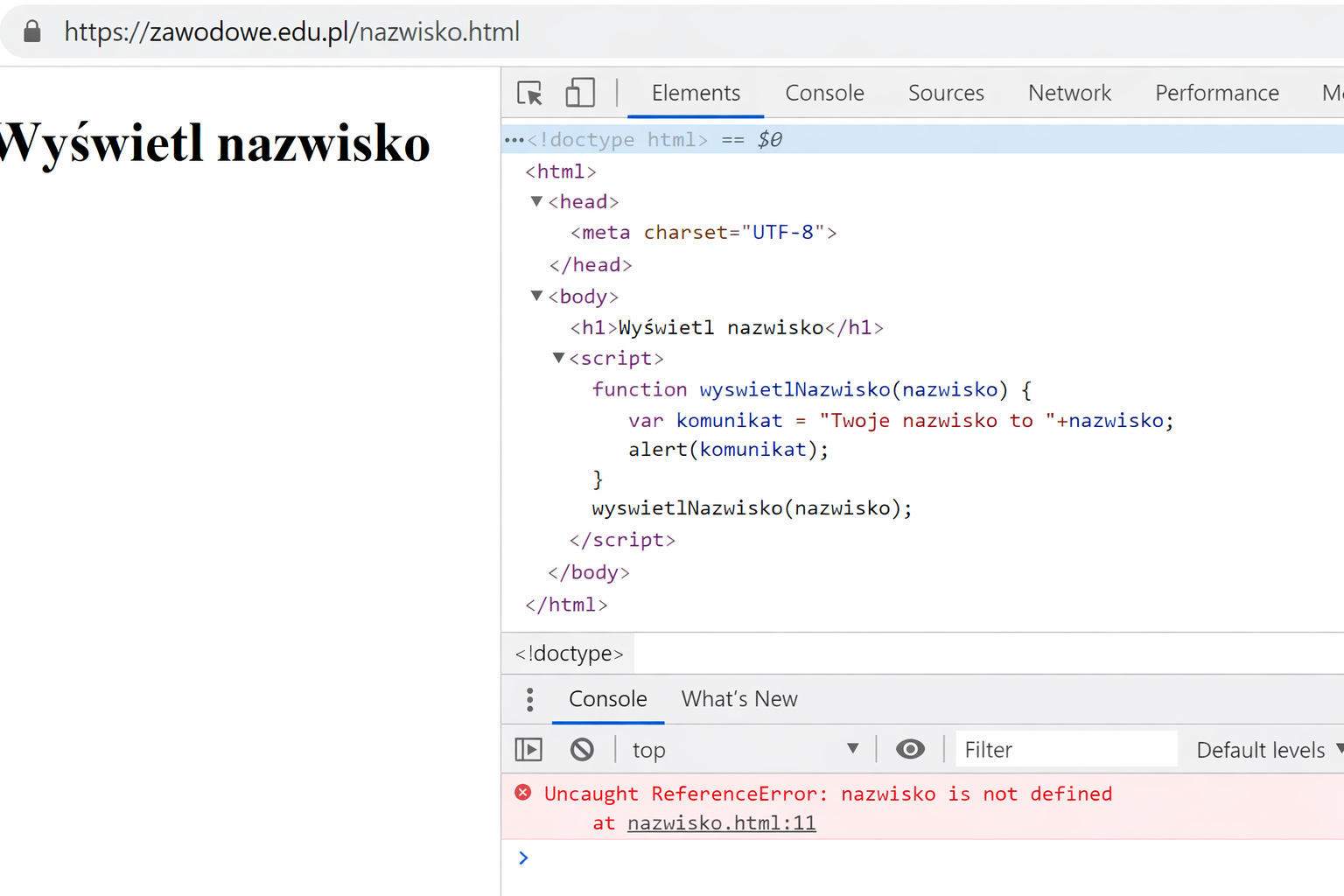
Które reguły CSS poprawnie ustawiają dla akapitu czcionkę Arial, rozmiar 16 pt i pochylenie (kursywę)?
A.
p { font-style: Arial; font-size: 16pt; font-variant: normal; }
B.
p { font-style: Arial; size: 16px; font-weight: normal; }
C.
p { font-family: Arial; font-size: 16pt; font-style: italic; }
D.
p { font-family: Arial; font-size: 16px; font-variant: normal; }
Wygląd czcionki opisują w CSS trzy osobne właściwości:
font-family ustala krój (np. Arial), font-size - rozmiar (tu 16pt, bo zadano punkty, a nie piksele), a font-style: italic włącza pochylenie. Razem daje to p { font-family: Arial; font-size: 16pt; font-style: italic; }. Warto pamiętać, że font-style odpowiada za kursywę, a font-weight za grubość - to częste źródło pomyłek. Dlatego poprawny jest ten zestaw reguł.