Odtwarzaj przebieg egzaminu krok po kroku i ucz się na własnych błędach. Widzisz dokładnie, w jakiej kolejności rozwiązywałeś pytania, ile czasu spędziłeś nad każdym z nich i kiedy zmieniałeś odpowiedzi.
Co znajdziesz na stronie przebiegu:
Suwak czasu
Przesuwaj i przeglądaj pytania w kolejności, w jakiej je rozwiązywałeś
Tryb nauki
Włącz, aby zobaczyć poprawne odpowiedzi i wyjaśnienia do pytań
Analiza czasu
Sprawdź, ile czasu spędziłeś nad każdym pytaniem i gdzie traciłeś czas
Monitoring focusu
Widzisz momenty, gdy opuściłeś zakładkę - tak jak widzi to nauczyciel
Proces przetwarzania sygnału wejściowego w czasie, wykorzystujący zasadę superpozycji, jest związany z filtrem
A. liniowym
B. przyczynowym
C. o skończonej odpowiedzi impulsowej
D. niezmiennym w czasie
Filtr liniowy to taki, który w procesie przetwarzania sygnału spełnia zasadę superpozycji. Oznacza to, że wynik działania filtru na sumie sygnałów wejściowych jest równy sumie wyników działania filtru na poszczególne sygnały. W praktyce, filtry liniowe są powszechnie stosowane w różnych zastosowaniach, takich jak audio, telekomunikacja czy przetwarzanie obrazu, co wynika z ich zdolności do efektywnej analizy sygnałów. Przykładowo, w systemach audio, filtry liniowe mogą być używane do eliminacji szumów czy wzmacniania określonych częstotliwości, co pozwala na uzyskanie lepszej jakości dźwięku. Zgodnie z dobrą praktyką inżynieryjną, projektowanie filtrów liniowych opiera się na zrozumieniu ich charakterystyki częstotliwościowej oraz odpowiedzi impulsowej, co jest kluczowe dla osiągnięcia zamierzonych efektów w przetwarzaniu sygnałów.
Pytanie 2
Element <meta charset="utf-8"> definiuje metadane odnoszące się do strony internetowej dotyczące
A. opisu witryny
B. kodowania znaków
C. języka używanego na stronie
D. słów kluczowych
Element <meta charset="utf-8"> jest kluczowym składnikiem metadanych w dokumentach HTML, który określa sposób kodowania znaków używanych na stronie internetowej. Użycie kodowania UTF-8, które jest najczęściej stosowanym standardem, pozwala na wyświetlanie różnorodnych znaków z różnych języków, w tym znaków diakrytycznych. Dzięki temu, strony internetowe mogą być dostępne dla szerokiego grona użytkowników bez obaw o błędy związane z wyświetlaniem tekstu. Kiedy przeglądarka internetowa napotyka ten element, wie, że powinna interpretować zawartość dokumentu zgodnie z określonym kodowaniem. Jest to szczególnie ważne w kontekście globalizacji internetu, gdzie treści mogą być tworzone w wielu językach. Ustalając odpowiednie kodowanie, programiści minimalizują ryzyko wystąpienia problemów z wyświetlaniem, takich jak zamienione znaki czy nieczytelne fragmenty tekstu. Właściwe ustawienie metadanych jest zgodne z wytycznymi W3C oraz zaleceniami dla twórców stron internetowych, co czyni ten element niezbędnym w każdej współczesnej witrynie.
Pytanie 3
W przedstawionym kodzie HTML, zaprezentowany styl CSS jest stylem:
<p style="color:red;">To jest przykładowy akapit.</p>
A. nagłówkowym
B. zewnętrznym
C. dynamicznym
D. lokalnym
Styl zewnętrzny odnosi się do stylów zapisanych w osobnym pliku CSS który jest załączany do dokumentu HTML za pomocą znacznika link w sekcji head. Taki sposób organizacji stylów umożliwia centralne zarządzanie wyglądem wielu stron jednocześnie co jest efektywne przy większych projektach. Styl nagłówkowy to styl umieszczony w sekcji head dokumentu HTML w znacznika style. Pozwala on na zdefiniowanie stylów dla całego dokumentu lecz wciąż ogranicza się do pojedynczej strony. Pomaga to w zachowaniu spójności wizualnej na stronie ale nie zapewnia tego na poziomie całego serwisu jak style zewnętrzne. Styl dynamiczny zazwyczaj odnosi się do stylów zmieniających się w odpowiedzi na akcje użytkownika często za pośrednictwem JavaScript lub CSS3. Przykładem może być zmiana koloru przycisku po najechaniu kursorem co zwykle osiągamy za pomocą pseudo-klas CSS jak :hover. W analizowanym kodzie styl CSS jest przypisany bezpośrednio do elementu HTML co jest typowym przykładem stylu lokalnego ponieważ nie jest zdefiniowany ani w zewnętrznym pliku ani w sekcji head dokumentu ani nie reaguje dynamicznie na akcje użytkownika. Zrozumienie różnic między tymi podejściami jest kluczowe dla efektywnego kodowania i stylizacji stron internetowych ze względu na różne potrzeby w projektach webowych. Właściwy wybór metody stylizacji wpływa na łatwość utrzymania i skalowalność projektu w miarę rozwoju strony internetowej. W praktyce stosowanie stylów lokalnych powinno być ograniczone do minimum ze względu na trudności w zarządzaniu i potencjalne konflikty z innymi stylami w większych projektach.
Pytanie 4
Jaką transformację w CSS zastosujemy, aby tylko pierwsze litery wszystkich słów stały się wielkie?
A. lowercase
B. uppercase
C. underline
D. capitalize
Odpowiedź 'capitalize' jest prawidłowa, ponieważ w CSS odnosi się do właściwości text-transform, która umożliwia manipulację sposobem wyświetlania tekstu. Użycie 'capitalize' powoduje, że pierwsza litera każdego wyrazu w danym elemencie HTML zostaje zmieniona na wielką literę. Na przykład, jeśli mamy tekst "przykład tekstu", zastosowanie 'text-transform: capitalize;' przekształci go na "Przykład Tekstu". Jest to szczególnie przydatne w tworzeniu estetycznych nagłówków lub list, gdzie chcemy, aby każde słowo zaczynało się od wielkiej litery. W kontekście dobrych praktyk, używanie transformacji tekstu powinno być zgodne z zasadami dostępności, aby nie wpłynęło negatywnie na odczyt tekstu przez technologie wspomagające. Warto także pamiętać, że 'capitalize' działa na każdy wyraz, co czyni go bardziej elastycznym w kontekście stylizacji niż inne opcje, takie jak 'uppercase', które zmieniają wszystkie litery na duże, co mogłoby zniekształcić zamierzony przekaz tekstowy.
Pytanie 5
W kodzie źródłowym zapisanym w języku HTML wskaż błąd walidacji dotyczący tego fragmentu: ```
CSS
Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący ...```
A. Nieznany znacznik h6.
B. Znacznik zamykający /b niezgodny z zasadą zagnieżdżania.
C. Znacznik br nie może występować wewnątrz znacznika p.
D. Znacznik br nie został poprawnie zamknięty.
Rozważmy błędne koncepcje zawarte w innych odpowiedziach. Wskazanie, że znacznik br nie został poprawnie zamknięty, jest niepoprawne, ponieważ znacznik <br> jest samozamykający i nie wymaga dodatkowego znacznika zamykającego. Często błędem jest próba zamknięcia takich znaczników, co prowadzi do niepotrzebnego zamieszania w kodzie. Dodatkowo, stwierdzenie, że znacznik br nie może występować wewnątrz znacznika p, jest nieprawidłowe. Zgodnie ze standardami HTML, znacznik <br> jest dozwolony wewnątrz <p> i służy do wprowadzenia przerwy linii. Wreszcie, znacznik <h6> jest prawidłowym znacznikiem HTML i jego użycie nie stanowi błędu. Pomyłka ta wynika prawdopodobnie z niepełnej znajomości dostępnych znaczników HTML. Dlatego zawsze warto poszerzać swoją wiedzę na ten temat i regularnie odnosić się do specyfikacji HTML.
Pytanie 6
Jakie jest określenie na element bazy danych, który umożliwia jedynie przeglądanie danych, przedstawiając je w formie tekstowej lub graficznej?
A. Tabela
B. Raport
C. Zapytanie
D. Formularz
Tabela to struktura bazy danych, która służy do przechowywania danych w formie zorganizowanej w wiersze i kolumny. Tabele są fundamentem relacyjnych baz danych, jednak nie umożliwiają one bezpośredniego generowania raportów ani wizualizacji danych. Tabele są wykorzystywane w procesie wprowadzania i edycji danych, a nie w ich przetwarzaniu do analizy. Zapytanie to forma polecenia, która umożliwia użytkownikowi pobieranie określonych danych z bazy, na podstawie zdefiniowanych kryteriów. Mimo że zapytania są kluczowe w procesie obróbki danych, same w sobie nie generują raportów ani wykresów, lecz zwracają wyniki w postaci zbioru danych. Formularz to narzędzie, które służy do wprowadzania i edytowania danych w bazie. Rola formularzy polega na ułatwieniu interakcji użytkownika z bazą danych poprzez umożliwienie wprowadzania informacji w zorganizowanej formie. Formularze są przydatne w procesach zarządzania danymi, ale ich funkcjonalność nie obejmuje analizy ani prezentacji danych w formie raportów. W związku z tym, zarówno tabela, jak i zapytanie oraz formularz nie spełniają kryteriów określonych w pytaniu, ponieważ nie są dedykowane wyłącznie do odczytu danych w formie raportów.
Pytanie 7
Język JavaScript wspiera
A. obiekty DOM
B. wysyłanie ciastek z identycznymi informacjami do wielu użytkowników strony
C. funkcje wirtualne
D. abstrakcyjne klasy
Wybór jednej z pozostałych opcji może wynikać z nieporozumienia dotyczącego podstawowych koncepcji programowania w JavaScript. Funkcje wirtualne, które są bardziej charakterystyczne dla języków programowania obiektowego, takich jak C++ czy Java, nie mają zastosowania w JavaScript, który nie wspiera klasycznej hierarchii klas w taki sposób, jak te języki. W JavaScript funkcje są obiektami, a prototypowe dziedziczenie jest kluczowym mechanizmem, co często prowadzi do mylnej interpretacji koncepcji klas abstrakcyjnych. JavaScript nie definiuje klas abstrakcyjnych w tradycyjnym sensie, chociaż od ES6 wprowadzono wsparcie dla klas. Co więcej, idea wysyłania ciastek z tą samą informacją do wielu klientów nie jest bezpośrednio związana z językiem JavaScript, lecz z mechanizmami serwerowymi oraz strukturyzowaniem danych w aplikacjach webowych. Często popełniane błędy myślowe dotyczą zrozumienia ról różnych technologii webowych i ich interakcji. JavaScript działa głównie po stronie klienta, a jego integracja z serwerami odbywa się zazwyczaj za pomocą protokołu HTTP, w którym ciasteczka są jednym z wielu elementów zarządzania stanem użytkownika. Zrozumienie roli DOM w kontekście JavaScript jest kluczowe do tworzenia efektywnych i interaktywnych aplikacji, co podkreśla znaczenie tej koncepcji w codziennym programowaniu.
Rozważmy, dlaczego inne odpowiedzi są niepoprawne. Pierwsza z nich sugeruje, że pętla wstawi do tablicy sekwencję od 0 do 10, co implikuje iterację, która zwiększa zmienną o 1. Jednak w analizowanym kodzie zmienna $x jest zwiększana o 10. Natomiast druga odpowiedź zakłada, że wartości w tablicy będą rosnąć od 0 do 9 co również wskazuje na niepełne zrozumienie mechanizmu działania pętli i inkrementacji zmiennej $x. Z kolei ostatnia odpowiedź sugeruje że do tablicy zostaną wstawione liczby kończące się na 100. To wskazuje na błędne przetworzenie pętli, w której zakres wartości $x nigdy nie dochodzi do 100 w żadnym z kroków iteracji. Typowym błędem myślowym w tych przypadkach jest niezrozumienie jak wartość zmiennej $x jest zmieniana w każdym kroku pętli oraz jak indeksy tablicy są przypisywane. Kluczowym elementem prawidłowego zrozumienia działania tego kodu jest dostrzeżenie, że pętla for kontroluje liczbę iteracji, a zmienna $x jest modyfikowana zgodnie z wyrażeniem $x=$x+10 przy każdym obrocie, co prowadzi do systematycznego zwiększania wartości dodawanej do tablicy.
Pytanie 9
Relacja opisana jako: "Rekord z tabeli A może odpowiadać wielu rekordom z tabeli B. Każdemu rekordowi z tabeli B przyporządkowany jest dokładnie jeden rekord z tabeli A" jest relacją
A. jeden do jednego
B. nieoznaczoną
C. wiele do wielu
D. jeden do wielu
Relacja typu jeden do wielu oznacza, że jeden rekord z jednej tabeli (w tym przypadku tabela A) może być powiązany z wieloma rekordami z innej tabeli (tabela B). W opisanej sytuacji rekord z tabeli A może odpowiadać dowolnej liczbie rekordów z tabeli B, co ilustruje tę relację. Przykładem takiej relacji może być baza danych systemu zarządzania szkołą, gdzie jeden nauczyciel (rekord z tabeli A) może uczyć wielu uczniów (rekordy z tabeli B), ale każdy uczeń jest przypisany do jednego nauczyciela. Przy projektowaniu baz danych, stosowanie odpowiednich relacji jest kluczowe dla integralności i wydajności systemu. Dbałość o takie relacje przyczynia się do poprawy jakości danych oraz minimalizacji redundancji, co jest zgodne z zasadami normalizacji baz danych. W praktyce, relacje jeden do wielu są powszechnie stosowane w systemach CRM, ERP oraz wielu innych aplikacjach, które wymagają organizacji danych w sposób logiczny i praktyczny.
Pytanie 10
Aby usunąć nienaturalne wygładzanie ukośnych krawędzi w grafice rastrowej, czyli tak zwane schodkowanie, konieczne jest wykorzystanie filtru
A. antyaliasingu
B. szumu
C. pikselizacji
D. gradientu
Antyaliasing to technika stosowana w grafice rastrowej, która ma na celu wygładzenie krawędzi obiektów, co z kolei redukuje efekt schodkowania. Schodkowanie, zwane również jagged edges, to zjawisko, w którym krawędzie linii wyglądają na poszarpane i nienaturalne, co jest szczególnie zauważalne przy nachylonych liniach lub krzywych. Antyaliasing działa na zasadzie wygładzania krawędzi poprzez mieszanie kolorów pikseli na granicy obiektu z kolorami pikseli tła, co tworzy iluzję płynności. Przykładem zastosowania antyaliasingu jest grafika komputerowa w grach, gdzie zapewnia on bardziej realistyczny obraz, a także przy renderowaniu grafik wektorowych do rastrowych. W standardach branżowych, takich jak OpenGL i DirectX, zastosowanie antyaliasingu jest zalecane, aby poprawić jakość wizualną i doświadczenia użytkowników. Zastosowanie technik takich jak MSAA (Multisample Anti-Aliasing) lub FXAA (Fast Approximate Anti-Aliasing) jest powszechną praktyką w nowoczesnych aplikacjach graficznych.
Pytanie 11
Utworzono bazę danych z tabelą mieszkańcy, która zawiera pola: nazwisko, imię oraz miasto. Następnie przygotowano poniższe zapytanie do bazy: SELECT nazwisko, imie FROM mieszkańcy WHERE miasto='Poznań' UNION ALL SELECT nazwisko, imie FROM mieszkańcy WHERE miasto='Kraków'; Wskaż zapytanie, które zwróci takie same dane.
A. SELECT nazwisko, imie FROM mieszkańcy AS 'Poznań' OR 'Kraków';
B. SELECT nazwisko, imie FROM mieszkańcy WHERE miasto HAVING 'Poznań' OR 'Kraków';
C. SELECT nazwisko, imie FROM mieszkańcy WHERE miasto BETWEEN 'Poznań' OR 'Kraków';
D. SELECT nazwisko, imie FROM mieszkańcy WHERE miasto='Poznań' OR miasto='Kraków';
Wybór odpowiedzi SELECT nazwisko, imie FROM mieszkańcy WHERE miasto='Poznań' OR miasto='Kraków' jest prawidłowy, ponieważ wykorzystuje operator logiczny OR, który umożliwia filtrowanie danych z tabeli mieszkańcy na podstawie wartości w polu miasto. To zapytanie zwraca wszystkich mieszkańców, którzy są z Poznania lub Krakowa, co odpowiada wymaganiom postawionym w pytaniu. Warto zauważyć, że taka konstrukcja jest efektywna, ponieważ nie używa złożonych zapytań ani nie tworzy zbiorów, które następnie muszą być łączone. Operator OR jest powszechnie stosowany w SQL do łączenia wielu warunków, co czyni go łatwym w użyciu. Dodatkowo, zgodnie z dobrymi praktykami baz danych, unikanie zbędnych operacji, jak UNION, gdy wystarczy proste OR, zwiększa wydajność i czytelność zapytań. Przykładowe zastosowanie tego zapytania może mieć miejsce w aplikacjach, które potrzebują zidentyfikować użytkowników z konkretnego regionu, co jest istotne w przypadku personalizacji treści lub promocji regionalnych.
Pytanie 12
Jakie imiona spełniają warunki klauzuli LIKE w zapytaniu?
SELECTimieFROMmieszkancyWHEREimieLIKE'_r%';
A. Krzysztof, Krystyna, Romuald
B. Rafał, Rebeka, Renata, Roksana
C. Gerald, Jarosław, Marek, Tamara
D. Arleta, Krzysztof, Krystyna, Tristan
Zapytanie SQL wykorzystuje klauzulę LIKE, która pozwala na wyszukiwanie wzorców w danych tekstowych. W tym przypadku wzór '_r%' oznacza, że szukamy imion, które mają na drugiej pozycji literę 'r' i mogą mieć dowolne znaki po tej literze. W analizowanych imionach, Arleta, Krzysztof, Krystyna oraz Tristan spełniają ten warunek, ponieważ: Arleta ma 'r' na drugiej pozycji, Krzysztof również, Krystyna także, a Tristan ma 'r' na drugiej pozycji. Przykład użycia klauzuli LIKE jest szczególnie przydatny w systemach, gdzie często zachodzi potrzeba filtrowania danych tekstowych na podstawie określonych wzorców. W praktyce, stosowanie klauzuli LIKE w zapytaniach SQL powinno być zgodne z najlepszymi praktykami, takimi jak optymalizacja indeksów i unikanie nadmiernego używania znaków wieloznacznych, które mogą prowadzić do spadku wydajności. Warto również pamiętać, że w wielu systemach baz danych klauzula LIKE jest czuła na wielkość liter, co może wpływać na wyniki zapytań.
Pytanie 13
Jakie obiekty w bazie danych służą do podsumowywania, prezentacji oraz drukowania danych?
A. zapytanie
B. zestawienie
C. raport
D. formularz
Zapytanie, formularz i zestawienie również są ważnymi elementami pracy z bazami danych, jednak żaden z tych obiektów nie spełnia wszystkich funkcji przypisywanych raportom. Zapytanie to instrukcja w języku zapytań, najczęściej SQL, która służy do pobierania danych z bazy danych. Choć zapytania mogą generować dane do późniejszego wykorzystania w raportach, same w sobie nie są narzędziem służącym do ich prezentacji ani podsumowywania. Formularz natomiast to struktura, która umożliwia użytkownikom wprowadzanie danych do bazy danych. Używa się go głównie do zbierania informacji, ale nie do ich analizy czy podsumowywania w formie raportów. Zestawienie to termin, który odnosi się do ogólnego podsumowania danych, ale również nie oferuje tak zaawansowanej i zorganizowanej prezentacji jak raport. Typowym błędem myślowym jest mylenie tych terminów, co może prowadzić do nieporozumień przy projektowaniu systemów informacyjnych. Ważne jest, aby zrozumieć, że każdy z tych elementów pełni inną rolę w zarządzaniu danymi. Aby poprawnie wykorzystać potencjał baz danych, należy umiejętnie dobierać narzędzia do konkretnego zadania.
Pytanie 14
W języku CSS zapis
h2 {background-color: green;}
spowoduje, że kolor zielony będzie dotyczył:
A. czcionki nagłówka drugiego stopnia
B. tła całej strony
C. czcionki każdego nagłówka na stronie
D. tła tekstu nagłówka drugiego stopnia
Odpowiedź, że kolor zielony będzie dotyczył tła tekstu nagłówka drugiego stopnia, jest poprawna. W kodzie CSS, zapis <b>h2 {background-color: green;}</b> oznacza, że wszystkie elementy <h2> na stronie będą miały tło w kolorze zielonym. W praktyce oznacza to, że każdy nagłówek drugiego stopnia będzie miał zielone tło, co może być użyteczne do wyróżnienia sekcji na stronie. Warto zauważyć, że stylowanie tła nagłówków może poprawić czytelność i estetykę dokumentu, zwłaszcza w sytuacjach, gdy chcemy podkreślić różne sekcje treści. Dobrą praktyką w CSS jest także używanie klas i identyfikatorów do bardziej precyzyjnego stylowania, co pozwala na unikanie konfliktów z innymi stylami na stronie. Dodatkowo, można eksperymentować z różnymi kolorami i przezroczystościami, aby uzyskać unikalne efekty wizualne, co jest szczególnie ważne w nowoczesnym projektowaniu stron internetowych.
Pytanie 15
Podaj słowo kluczowe w języku C++, które umieszczane przed wbudowanym typem danych, umożliwia przyjmowanie jedynie nieujemnych wartości liczbowych?
A. unsigned
B. const
C. short
D. long
W języku C++ istnieją różne słowa kluczowe, które mogą wprowadzać pewne zamieszanie, jeśli chodzi o typy danych. Na przykład, słowo kluczowe 'short' zmniejsza rozmiar zmiennej, ale nie wpływa na to, czy zmienna przechowuje wartości ujemne czy nie. 'short int' może nadal przechowywać wartości zarówno dodatnie, jak i ujemne, a jego zastosowanie ma sens jedynie w kontekście zmniejszenia zajmowanej pamięci, co w niektórych przypadkach może być korzystne dla optymalizacji. Kolejne słowo kluczowe, 'const', z kolei nie ma wpływu na zakres wartości zmiennej, lecz określa, że zmienna jest stała i niezmienna po jej inicjalizacji. Użycie 'const' jest szczególnie przydatne w kontekście zapewnienia, że dane nie zostaną zmienione w trakcie działania programu, co może poprawić stabilność i przewidywalność aplikacji. 'Long' jest słowem kluczowym, które rozszerza zakres przechowywanych wartości, ale wciąż nie zapewnia, że będą one jedynie nieujemne. Wartość zmiennej 'long int' może być zarówno dodatnia, jak i ujemna. Typowe błędy myślowe związane z wyborem niepoprawnych słów kluczowych mogą wynikać z niepełnego zrozumienia tego, jak różne modyfikatory wpływają na typy danych, co z kolei prowadzi do pomyłek w kodowaniu oraz potencjalnych błędów runtime w aplikacjach.
Pytanie 16
W języku PHP wykorzystano funkcję ```is_float()```. Które z poniższych wywołań tej funkcji zwróci rezultat true?
A. is_float('3,34')
B. is_float(NULL)
C. is_float(334)
D. is_float(3.34)
Zrozumienie, co dokładnie zwraca funkcja is_float(), jest bardzo ważne, jeśli chce się dobrze pracować z typami danych w PHP. Na przykład, jak wpiszesz is_float(334), to dostaniesz false, bo 334 to liczba całkowita, a nie zmiennoprzecinkowa. To może być mylące, bo nie każdy wie, że float to coś konkretnego. Podobnie jest z is_float(NULL) - zwraca false, bo NULL to jakby brak wartości, a nie liczba. Jeszcze jedno – jakbyś wywołał is_float('3,34'), to też dostaniesz false, bo PHP nie rozpozna tego jako float; to traktuje jako tekst. PHP nie konwertuje automatycznie tekstu na float, zwłaszcza jak używasz przecinka, zamiast kropki. Te błędy często biorą się stąd, że ludzie myślą, że PHP sam zrozumie, co mają na myśli. Dlatego warto ogarnąć, jak działa typowanie w PHP i jak używać funkcji tych sprawdzających typy, jak is_float(). Dzięki temu twój kod będzie bardziej stabilny i unikniesz błędów przy jego działaniu.
Pytanie 17
Kod JavaScript ma za zadanie szukanie wartości maksymalnej w tablicy. Wskaż błąd występujący w skrypcie.
A. Zastosowano operator porównania zamiast przypisania w linii 15.
B. Warunek w linii 16 powinien być odwrócony.
C. Zmienna max ma niewłaściwie przypisaną wartość w linii 14.
D. Kod zapisany w linii 20 ma nieprawidłową składnię.
Kod, który ma znaleźć wartość maksymalną w tablicy, jest w gruncie rzeczy poprawny algorytmicznie, a główny problem leży w składni pętli. Łatwo jednak skupić się na innych fragmentach i szukać błędu tam, gdzie go nie ma. Spójrzmy po kolei na wszystkie podejrzane miejsca. Warunek w instrukcji `if (max <= tablica[j])` może wyglądać podejrzanie, bo często w przykładach używa się operatora `<`. Jednak użycie `<=` nie jest błędem. To znaczy tylko tyle, że jeśli w tablicy występuje kilka identycznych wartości maksymalnych, to `max` przyjmie wartość ostatniego z nich. Algorytm nadal zwróci poprawne maksimum, różnica dotyczy jedynie tego, który indeks „wygra”, jeśli wartości są równe. Z punktu widzenia wyszukiwania największej liczby to zachowanie jest całkowicie akceptowalne. Pojawia się też pokusa, żeby winić linię z `document.write(...)`. Ten zapis jest składniowo poprawny w JavaScripcie: mamy wywołanie metody `write` na obiekcie `document` i konkatenację napisu z wartością zmiennej. Można dyskutować, czy jest to dobra praktyka w nowoczesnych aplikacjach (zwykle lepiej manipulować DOM, np. przez `textContent`), ale nie jest to błąd uniemożliwiający działanie programu. Podobnie przypisanie `max = tablica[0];` jest typowym i poprawnym sposobem inicjalizacji zmiennej maksimum: zakładamy na start, że największym elementem jest pierwszy element tablicy i dopiero później weryfikujemy to w pętli. Tu nie ma żadnej sprzeczności z logiką algorytmu. Prawdziwy problem to użycie operatora porównania `==` w miejscu, gdzie powinniśmy zainicjalizować licznik pętli. Konstrukcja `for (j == 1; j < 9; j++)` nie ustawia wartości `j`, tylko sprawdza, czy aktualne `j` jest równe 1, przez co cała pętla ma niepoprawną składnię. Typowy błąd myślowy polega tutaj na utożsamieniu „ustawienia na 1” z „sprawdzeniem, czy jest równe 1”. W językach imperatywnych to są zupełnie różne operacje. Dobra praktyka to zawsze czytać nagłówek pętli jak zdanie: „ustaw j na 1; dopóki j < 9; po każdej iteracji zwiększ j o 1”. Jeśli to czytanie nie ma sensu, znaczy że coś jest nie tak z operatorem. Warto też pamiętać, że narzędzia linterskie i tryb `use strict` pomagają wychwycić takie pomyłki, zanim trafią one do gotowego kodu.
Pytanie 18
Zamieszczony kod HTML formularza zostanie wyświetlony przez przeglądarkę w sposób:
Dokładnie tak powinien wyglądać ten formularz! Zwróć uwagę, jak HTML interpretuje znaczniki <br> – one wymuszają przejście do nowej linii, więc w kodzie wyjściowym każda sekcja obowiązków pojawi się osobno, pod sobą. To, że jeden z checkboxów ma atrybuty disabled oraz checked, powoduje, że jest domyślnie zaznaczony, ale nie można go odznaczyć ani zaznaczyć ponownie – to ważny niuans, bo czasem zapomina się, że disabled nie oznacza tylko „wyszarzony”, ale też „nie bierz udziału w wysyłaniu formularza”. Takie wykorzystanie checkboxów jest powszechne, szczególnie jeśli chcesz pokazać użytkownikowi pewne stałe informacje (np. obowiązek, którego nie można uniknąć). Z mojego doświadczenia, bardzo często w praktycznych projektach „disabled” stosuje się np. przy wymaganych oświadczeniach, gdzie użytkownik ma tylko do wglądu informację, że coś już jest włączone i nie może tego zmienić. No i jeszcze – checked przy pisaniu kodu powoduje, że checkbox jest domyślnie zaznaczony, co jest zgodne z kodem źródłowym. Same nazwy pól (czyli atrybuty name i value) zostaną wysłane do serwera tylko dla tych pól, które nie są disabled i użytkownik je zaznaczył. To też jest bardzo praktyczna rzecz, bo pozwala precyzyjnie sterować tym, co trafia do backendu. Moim zdaniem taka forma zapisu formularza to dobry punkt wyjścia do dalszej rozbudowy – łatwo dodać tutaj walidację, obsługę JavaScript czy zastosować style CSS. Trzymanie się tej składni ułatwia też potem pracę zespołową, bo jest czytelna i zgodna z oczekiwaniami innych programistów. Podsumowując, wybrałeś opcję najbliższą temu, co wyświetli przeglądarka na bazie danego kodu HTML – i to jest podejście zgodne ze standardami, doceniane w branży.
Pytanie 19
Czy automatyczna weryfikacja właściciela witryny korzystającej z protokołu HTTPS jest możliwa dzięki
A. certyfikatowi SSL
B. informacjom whois
C. prywatnym kluczom
D. danym kontaktowym zamieszczonym na stronie
Certyfikat SSL (Secure Sockets Layer) jest kluczowym elementem w automatycznej weryfikacji właściciela strony internetowej, który jest udostępniany przez protokół HTTPS. Głównym zadaniem certyfikatu SSL jest zapewnienie, że komunikacja między przeglądarką a serwerem jest zaszyfrowana oraz że tożsamość serwera została potwierdzona przez zaufaną stronę trzecią, czyli urząd certyfikacji (CA - Certificate Authority). Certyfikaty SSL są wydawane po przeprowadzeniu odpowiednich weryfikacji tożsamości wnioskodawcy, co może obejmować sprawdzenie danych WHOIS, ale również inne procesy weryfikacyjne, takie jak potwierdzenie adresu e-mail lub dokumentów właściciela firmy. Przykładowo, witryny e-commerce korzystają z certyfikatów SSL, aby zapewnić bezpieczeństwo transakcji finansowych, co zwiększa zaufanie użytkowników do sklepu. Na poziomie technicznym, certyfikat SSL implementuje protokoły kryptograficzne, takie jak TLS (Transport Layer Security), co nie tylko zabezpiecza transmisję danych, ale także umożliwia autoryzację strony. W praktyce, posiadanie certyfikatu SSL wpływa również na pozycjonowanie w wyszukiwarkach, ponieważ Google promuje strony z bezpiecznym połączeniem HTTPS.
Pytanie 20
Wskaź komentarz, który zajmuje wiele linii, w języku PHP?
A. #
B. / /
C. <!-- -->
D. /* */
Komentarze wieloliniowe w języku PHP są definiowane za pomocą znaków '/*' na początku i '*/' na końcu bloku tekstu, co pozwala na umieszczanie komentarzy obejmujących wiele linii. Tego rodzaju komentarze są niezwykle przydatne w sytuacjach, gdy chcemy opisać bardziej złożone fragmenty kodu, jak również w celu wyłączenia większych sekcji kodu podczas debugowania. Komentarze wieloliniowe są zgodne ze standardem PHP, co czyni je preferowanym rozwiązaniem w wielu projektach programistycznych. Przykład użycia: /* To jest komentarz komentarz wieloliniowy w PHP */. W odróżnieniu od komentarzy jedno-liniowych, które są ograniczone do jednej linii (używając // lub #), komentarze wieloliniowe umożliwiają umieszczanie dłuższych opisów. Ważne jest, aby używać komentarzy z umiarem, aby kod pozostał czytelny i zrozumiały dla innych programistów oraz dla przyszłych wersji projektu.
Pytanie 21
Zastosowanie poniższej kwerendy SQL spowoduje usunięcie
DELETEFROMmieszkaniaWHEREstatus=1;
A. tabel, w których pole status ma wartość 1, z bazy danych mieszkania
B. rekordów, dla których pole status ma wartość 1, z tabeli mieszkania
C. pola o nazwie status w tabeli mieszkania
D. tabeli mieszkania z systemu baz danych
Odpowiedź, którą zaznaczyłeś, jest jak najbardziej trafna i dotyczy działania kwerendy SQL, szczególnie polecenia DELETE. W tym przypadku, to DELETE FROM mieszkania WHERE status=1 oznacza, że zamierzamy usunąć wszystkie rekordy z tabeli mieszkania, gdzie status jest równy 1. To jest ważne, bo w zarządzaniu bazami danych kluczowe jest precyzyjne ustalenie, które dane chcemy usunąć. Z mojej perspektywy, przed wykonaniem takiej operacji warto najpierw wykonać zapytanie SELECT z tymi samymi warunkami, żeby zobaczyć, co dokładnie usuniemy. Przykład? Możesz chcieć usunąć mieszkania, które są zarezerwowane lub niedostępne, co może być oznaczone statusem 1. To naprawdę dobra praktyka, bo pozwala na lepsze zarządzanie danymi i na utrzymanie porządku w bazie. A wiesz, co jeszcze? Zawsze warto zrobić kopię zapasową danych przed masowym usuwaniem, żeby nie stracić czegoś ważnego.
Pytanie 22
W przedstawionym filmie, aby połączyć tekst i wielokąt w jeden obiekt tak, aby operacja ta była odwracalna zastosowano funkcję
A. sumy.
B. grupowania.
C. części wspólnej.
D. wykluczenia.
Prawidłowo – w filmie została użyta funkcja grupowania. W grafice wektorowej, np. w programach typu Inkscape, CorelDRAW czy Illustrator, grupowanie służy właśnie do logicznego połączenia kilku obiektów w jeden „zestaw”, ale bez trwałego mieszania ich geometrii. To znaczy: tekst dalej pozostaje tekstem, wielokąt dalej jest wielokątem, tylko są traktowane jak jeden obiekt przy przesuwaniu, skalowaniu czy obracaniu. Dzięki temu operacja jest w pełni odwracalna – w każdej chwili możesz rozgrupować elementy i edytować każdy osobno. Moim zdaniem to jest podstawowa dobra praktyka w pracy z projektami, które mogą wymagać późniejszych poprawek: podpisy, etykiety, logotypy, schematy techniczne. Jeśli połączysz tekst z kształtem za pomocą operacji boolowskich (suma, część wspólna, wykluczenie), to tekst zwykle zamienia się na krzywe, przestaje być edytowalny jako tekst. To bywa potrzebne przy przygotowaniu do druku czy eksportu do formatu, który nie obsługuje fontów, ale nie wtedy, gdy zależy nam na łatwej edycji. Z mojego doświadczenia: przy projektowaniu interfejsów, ikon, prostych banerów na WWW czy grafik do multimediów, najrozsądniej jest najpierw grupować logicznie elementy (np. ikona + podpis), a dopiero na samym końcu, gdy projekt jest ostateczny, ewentualnie zamieniać tekst na krzywe. Grupowanie pozwala też szybko zaznaczać całe moduły projektu, wyrównywać je względem siebie, duplikować całe zestawy (np. kafelki menu, przyciski z opisami) bez ryzyka, że coś się rozjedzie. W grafice komputerowej to taka podstawowa „organizacja pracy” – mniej destrukcyjna niż różne operacje na kształtach i zdecydowanie bardziej elastyczna przy późniejszych zmianach.
Pytanie 23
W języku HTML, aby uzyskać następujący efekt formatowania pogrubiony pochylony lub w górnym indeksie należy zapisać kod:
A. <b>pogrubiony <i>pochylony</i></b> lub w <sup>górnym indeksie</sup>
B. <i>pogrubiony </i><b>pochylony </b>lub w <sub>górnym indeksie</sub>
C. <i>pogrubiony <b>pochylony lub w </i><sup>górnym indeksie</sup>
D. <b>pogrubiony </b><i>pochylony</i> lub w <sup>górnym indeksie</sup>
Odpowiedź, w której użyłeś znaczników <b> i <i> w odpowiednich miejscach, jest całkiem dobra. Znak <b> jest świetny do pogrubiania tekstu, co przydaje się, gdy chcesz podkreślić coś ważnego. Natomiast <i> pozwala na pochylanie tekstu, co dodaje mu charakteru i może sugerować cytaty czy tytuły. Co ciekawe, znacznik <sup> stosujemy, gdy chcemy pokazać górny indeks, np. przy potęgach czy jednostkach miar. Przykład takiego użycia byłby taki: <b>Waga</b> <i>w kilogramach</i> wynosi <sup>2</sup> dla dwóch jednostek. Jak widać, stosowanie HTML w odpowiedni sposób pozwala robić czytelne i estetyczne prezentacje, co jest zgodne z dobrymi praktykami w web designie oraz standardami W3C. Warto też pamiętać, że dobrze dobrane znaczniki mają znaczenie nie tylko wizualne, ale także pomagają w indeksowaniu treści przez wyszukiwarki, co z kolei wpływa na SEO.
Pytanie 24
W języku PHP funkcja trim służy do
A. Porównywania dwóch tekstów i wyświetlania ich wspólnej części
B. Usuwania białych znaków lub innych znaków wymienionych w parametrze z obu końców tekstu
C. Określania długości tekstu
D. Redukowania długości tekstu o określoną w parametrze liczbę znaków
Wybór odpowiedzi, która sugeruje, że funkcja trim w PHP zmniejsza napis o wskazaną w parametrze liczbę znaków, jest błędny. Funkcja ta nie ma na celu manipulacji długością napisu w taki sposób, ale raczej skupia się na usuwaniu zbędnych znaków z jego końców. Użytkownicy często mylą działanie trim z innymi funkcjami związanymi z obróbką łańcuchów tekstowych, co prowadzi do nieporozumień. Z kolei przekonanie, że trim porównuje dwa napisy i wypisuje ich część wspólną, jest także mylne, ponieważ nie dostarcza funkcjonalności porównywania tekstów. PHP oferuje inne funkcje, takie jak strcmp, które są przeznaczone do porównywania łańcuchów. Kolejna nieprawidłowa koncepcja to założenie, że trim służy do podawania długości napisu - na to zadanie są dedykowane inne funkcje, jak strlen. Różne funkcje w PHP mają specyficzne zastosowania, co jest istotne w kontekście dobrych praktyk programistycznych, ponieważ stosowanie niewłaściwych funkcji może prowadzić do nieefektywności i błędów w kodzie. Warto zatem dokładnie zapoznawać się z dokumentacją PHP i zrozumieć, jakie są cele i zastosowania konkretnych funkcji, aby uniknąć typowych pułapek i błędów w programowaniu.
Pytanie 25
Poniższe zapytanie SQL ma na celu:
UPDATEUczenSETid_klasy=id_klasy+1;
A. zwiększyć o jeden wartość pola Uczen
B. ustawić wartość pola Uczen na 1
C. zwiększyć o jeden wartość kolumny id_klasy dla wszystkich wpisów w tabeli Uczen
D. przypisać wartość kolumny id_klasy jako 1 dla wszystkich wpisów w tabeli Uczen
Polecenie SQL "UPDATE Uczen SET id_klasy = id_klasy + 1;" jest poprawne, ponieważ wskazuje na aktualizację kolumny 'id_klasy' w tabeli 'Uczen'. Wartość kolumny dla każdego rekordu w tabeli zostanie zwiększona o jeden. Działanie to jest przydatne w sytuacjach, gdy chcemy zaktualizować dane, na przykład po przesunięciu uczniów do wyższej klasy w systemie edukacyjnym. Przy takim podejściu, wszyscy uczniowie w danym roku szkolnym mogą zostać automatycznie przeniesieni do następnej klasy bez konieczności edytowania rekordów pojedynczo, co zwiększa efektywność i zmniejsza ryzyko błędów. Ta praktyka jest zgodna z zasadami optymalizacji baz danych, gdzie operacje masowe są preferowane dla ich wydajności. Ponadto, dobrym nawykiem jest tworzenie kopii zapasowych przed przeprowadzeniem masowych aktualizacji, aby uniknąć nieodwracalnych zmian w przypadku błędów.
Pytanie 26
Który standard video cechuje się rozdzielczością 1920 px na 1080 px?
A. HD Ready
B. 4K
C. Full HD
D. Ultra HD
Prawidłowa odpowiedź to „Full HD”, bo właśnie ten standard oznacza rozdzielczość 1920 × 1080 pikseli w proporcjach 16:9. W praktyce, gdy mówimy o filmach na YouTube, streamach, nagraniach z kamery czy materiałach promocyjnych na stronę WWW, opcja 1080p to właśnie Full HD. Litera „p” oznacza skanowanie progresywne (progressive), czyli wyświetlanie całych klatek po kolei, co daje płynniejszy obraz niż przeplot („i” jak interlaced). W branży webowej Full HD to taki „złoty standard” jakości wideo – pliki mają jeszcze rozsądny rozmiar, a obraz jest już bardzo szczegółowy, więc nadaje się zarówno do odtwarzania w przeglądarce, jak i do osadzania w prezentacjach czy materiałach e‑learningowych. Moim zdaniem, przy projektowaniu serwisu z treściami multimedialnymi, warto domyślnie przygotowywać materiały właśnie w 1920×1080 i ewentualnie generować niższe wersje (np. 1280×720) dla urządzeń mobilnych lub słabszych łączy. W pracy grafika czy twórcy stron WWW dobrze jest też kojarzyć nazwy standardów: HD Ready to 1280×720, Full HD to 1920×1080, a 4K/Ultra HD to okolice 3840×2160. Dzięki temu łatwiej dobrać odpowiedni format eksportu z programów typu Premiere, DaVinci Resolve czy nawet z prostszych edytorów online. Z doświadczenia powiem, że klienci często mówią „chcę film w HD”, a mają na myśli właśnie Full HD, więc świadomość dokładnej rozdzielczości pomaga uniknąć nieporozumień i zbyt niskiej jakości materiałów.
Pytanie 27
W języku JavaScript trzeba sformułować warunek, który będzie spełniony, gdy zmienna a będzie dowolną liczbą naturalną dodatnią (więcej niż 0) lub gdy zmienna b będzie dowolną liczbą z przedziału domkniętego od 10 do 100. Wyrażenie logiczne w tym warunku powinno mieć postać
A. (a > 0) && ((b >= 10) && (b <= 100))
B. (a > 0) && ((b >= 10) || (b <= 100))
C. (a > 0) || ((b >= 10) && (b <= 100))
D. (a > 0) || ((b >= 10) || (b <= 100))
Poprawna odpowiedź (a > 0) || ((b >= 10) && (b <= 100)) uwzględnia wymaganie, aby warunek był spełniony, gdy zmienna a jest liczbą naturalną dodatnią bądź zmienna b znajduje się w przedziale od 10 do 100, włącznie. W tym przypadku użycie operatora logicznego '||' (lub) jest kluczowe, ponieważ wystarczy, że jeden z warunków będzie prawdziwy, aby cały warunek był spełniony. Przykładem może być skrypt walidujący dane wejściowe użytkownika: jeśli zmienna a przechowuje wartość 5 (czyli liczbę naturalną dodatnią), to niezależnie od wartości zmiennej b, warunek będzie prawdziwy. Analogicznie, jeśli a wynosi 0, a b = 15, warunek również będzie spełniony, ponieważ b mieści się w wymaganym przedziale. Taka konstrukcja warunku jest zgodna z dobrą praktyką programistyczną, gdyż pozwala na jasne i zrozumiałe określenie, kiedy pewne zasady powinny być stosowane. Zastosowanie operatorów logicznych w taki sposób wspiera tworzenie czytelnych i elastycznych warunków, co jest istotne w kontekście utrzymania kodu i jego przyszłych modyfikacji.
Pytanie 28
Jakiego wyniku można się spodziewać po wykonaniu zapytania na przedstawionej tabeli?
SELECTCOUNT(DISTINCT wykonawca) FROM`muzyka`;
ID
tytul_plyty
wykonawca
rok_nagrania
opis
1
Czas jak rzeka
Czesław Niemen
2005
Przyjdź W Taka Noc itp.
2
Ikona
Stan Borys
2014
3
Aerolit
Czesław Niemen
2017
Winylowa reedycja płyty "Aerolit"
4
Journey
Mikołaj Czechowski
2013
A. 4
B. 0
C. 1
D. 3
Zapytanie SELECT COUNT(DISTINCT wykonawca) FROM muzyka; ma na celu zliczenie unikalnych wykonawców w tabeli muzyka. Kluczowym błędem jest brak zrozumienia działania funkcji DISTINCT która eliminuje duplikaty i pozwala na zliczenie jedynie różniących się wartości. Należy zatem odrzucić wszelkie odpowiedzi sugerujące liczbę większą niż 3 ponieważ w tabeli są obecne tylko trzy unikalne wartości w kolumnie wykonawca: Czesław Niemen Stan Borys oraz Mikołaj Czechowski. Często popełnianym błędem jest mylne założenie że każda unikalna wartość w konkretnej kolumnie powinna być liczona wielokrotnie co odbiega od celu analizy unikalności danych. W kontekście administracji bazami danych i analizy SQL zrozumienie funkcji DISTINCT jest kluczowe dla dokładności raportowania i optymalizacji wydajności zapytań. Wiedza o tym jak działa COUNT w połączeniu z DISTINCT pomaga w skutecznym projektowaniu zapytań w celu uzyskania dokładnych wyników. Zastosowanie tej wiedzy jest niezbędne w analizie danych biznesowych i przy tworzeniu precyzyjnych raportów dla różnych interesariuszy. Poprawne zrozumienie i implementacja tego mechanizmu wspiera efektywne zarządzanie danymi i podejmowanie decyzji opartych na faktach. Przygotowanie do egzaminu powinno obejmować praktyczne zastosowanie tych koncepcji co ułatwi ich intuicyjne wykorzystanie w sytuacjach zawodowych.
Pytanie 29
Jakiego typu mechanizm zabezpieczeń aplikacji jest zawarty w środowisku uruchomieniowym platformy .NET Framework?
A. Mechanizm uruchamiania aplikacji dla bibliotek klas
B. Mechanizm uruchamiania aplikacji oparty na uprawnieniach kodu (CAS - Code Access Security) i na rolach (RBS - Role-Based Security)
C. Mechanizm uruchamiania aplikacji zrealizowany przez frameworki aplikacji webowych (ASP.NET)
D. Mechanizm uruchamiania aplikacji realizowany przez funkcję Windows API (Application Programming Interface)
Odpowiedzi sugerujące, że mechanizmy bezpieczeństwa w .NET Framework są realizowane przez bibliotekę klas, frameworki aplikacji internetowych (ASP.NET) oraz przez funkcje Windows API, są niepoprawne. Mechanizm wykonywania aplikacji dla bibliotek klas nie jest samodzielnym systemem kontroli bezpieczeństwa; oferują one zestaw funkcji i klas, które mogą być używane do rozwoju, ale nie zawierają w sobie wbudowanych zabezpieczeń. Również frameworki aplikacji internetowych, takie jak ASP.NET, wykorzystują różne techniki i standardy do zapewnienia bezpieczeństwa, ale same w sobie nie stanowią całościowego mechanizmu kontroli dostępu. Funkcje Windows API (Application Programming Interface) dostarczają niskopoziomowe interfejsy do interakcji z systemem operacyjnym, jednak ich rola w kontekście bezpieczeństwa aplikacji .NET jest ograniczona i nie odpowiada za zarządzanie uprawnieniami kodu. W rzeczywistości CAS i RBS są odpowiedzialne za zarządzanie dostępem do zasobów w .NET Framework, co czyni te mechanizmy kluczowymi dla zapewnienia bezpieczeństwa, podczas gdy pozostałe wymienione mechanizmy są bardziej złożonymi elementami większej architektury aplikacji i same w sobie nie oferują pełnej funkcjonalności ochrony przed nieautoryzowanym dostępem.
Pytanie 30
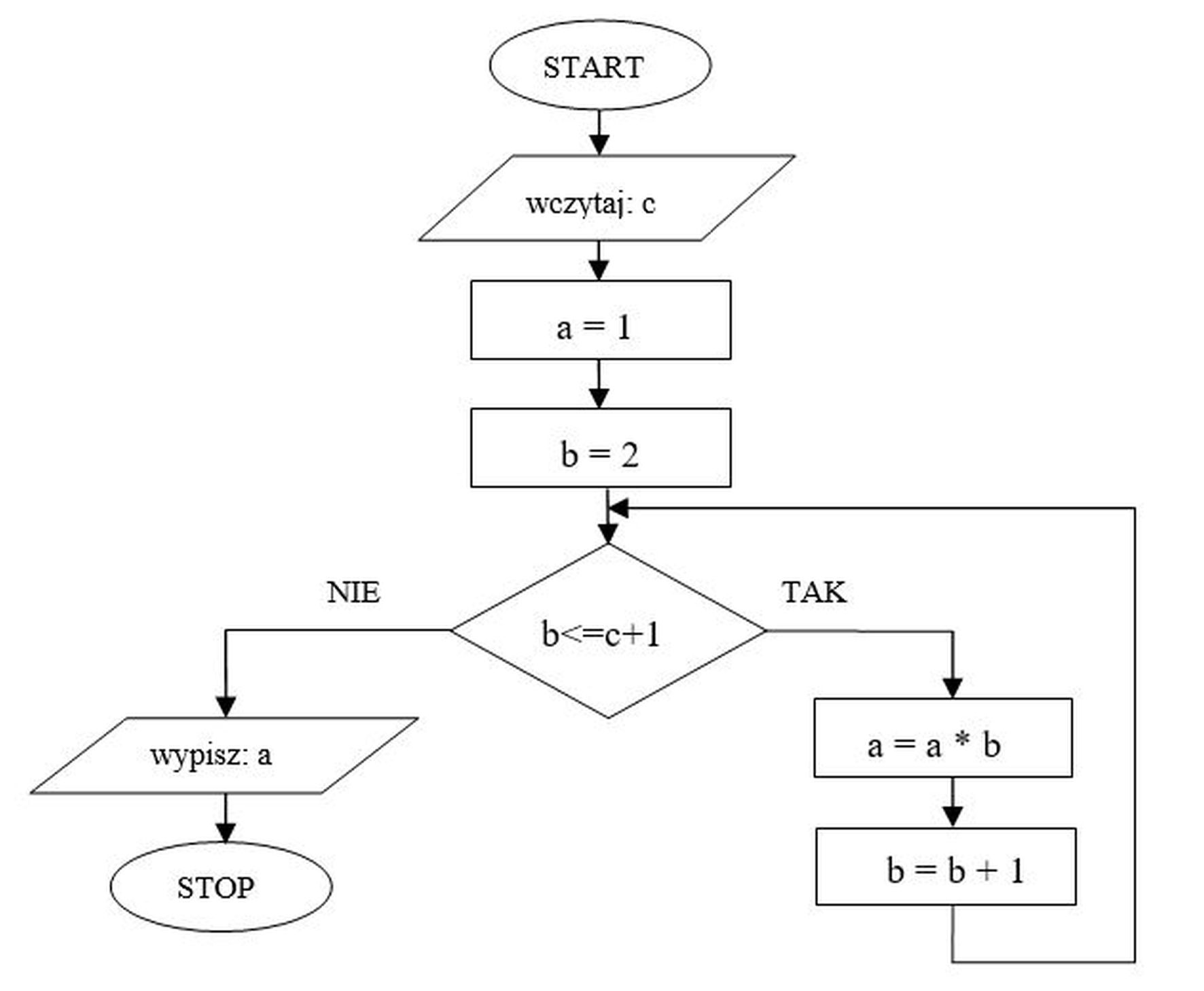
Wynikiem działania algorytmu dla c = 3 jest liczba
A. 24
B. 6
C. 12
D. 60
Poprawna odpowiedź 24 wynika z dokładnego prześledzenia działania algorytmu krok po kroku. Algorytm najpierw wczytuje wartość c, potem ustawia zmienne: a = 1 oraz b = 2. Następnie sprawdza warunek b <= c + 1. Dla c = 3 mamy c + 1 = 4, więc pętla działa tak długo, jak b <= 4. Teraz iteracje: 1) b = 2, 2 <= 4 – warunek spełniony, więc wykonujemy a = a * b, czyli a = 1 * 2 = 2, potem zwiększamy b: b = 3. 2) b = 3, 3 <= 4 – znowu TAK, więc a = 2 * 3 = 6, b zwiększa się do 4. 3) b = 4, 4 <= 4 – nadal TAK, więc a = 6 * 4 = 24, b rośnie do 5. 4) b = 5, 5 <= 4 – warunek już fałszywy, wychodzimy z pętli i wypisujemy a, czyli 24. W praktyce ten algorytm oblicza iloczyn kolejnych liczb naturalnych od 2 do c+1, czyli w tym przypadku 2 * 3 * 4. To jest po prostu część silni: 4! = 1 * 2 * 3 * 4, tylko bez początkowego 1, więc wynik jest taki sam. Warto tu zauważyć dobry nawyk: inicjacja zmiennej a wartością 1 jest klasycznym wzorcem przy obliczaniu iloczynów (neutralny element mnożenia). Tego typu konstrukcje pętli z warunkiem porównującym do c+1 pojawiają się bardzo często w programowaniu – zarówno w algorytmach obliczających silnię, jak i przy różnego rodzaju iteracjach po zakresach, np. w JavaScript czy PHP. Z mojego doświadczenia dobrze jest zawsze rozpisać sobie kolejne kroki na kartce, szczególnie gdy warunek zawiera dodawanie lub odejmowanie, bo to właśnie tam najłatwiej o pomyłkę o jeden krok (tzw. błąd off-by-one).
Pytanie 31
Kod w języku PHP przedstawia się następująco (patrz ramka): Zakładając, że zmienne a, b, c mają wartości numeryczne, wynik warunku będzie skutkował wypisaniem liczby:
if ($a>$b&&$a>$c)
echo$a;else if ($b>$c)
echo$b;elseecho$c;
A. nieparzystej.
B. najmniejszej.
C. największej.
D. parzystej.
Analizując niepoprawne odpowiedzi należy zwrócić uwagę na istotę działania warunków w kodzie PHP. Odpowiedź że wynik to najmniejsza liczba wynika z nieprawidłowego zrozumienia logiki porównań. Kod przede wszystkim analizuje która z trzech zmiennych jest największa poprzez sekwencyjne porównania. Wybór najmniejszej liczby wymagałby zupełnie innej konstrukcji polegającej na odwrotnym rozumowaniu co jest istotne w praktyce programowania przy rozwiązywaniu innych problemów algorytmicznych. Odpowiedzi dotyczące liczb parzystych i nieparzystych są błędne ponieważ nie istnieje w kodzie żadna logika sprawdzająca parzystość wartości. Aby sprawdzić parzystość zastosowalibyśmy operator modulo który umożliwia określenie reszty z dzielenia przez dwa. Typowy błąd myślowy to zakładanie że porównania liczb automatycznie uwzględniają ich właściwości arytmetyczne co jest nieprawdą. Warto zauważyć że dobra praktyka programistyczna wymaga precyzyjnego określenia co dokładnie ma być osiągnięte przez warunki w kodzie co podkreśla znaczenie zarówno analizy wymagań jak i implementacji rozwiązań.
Pytanie 32
W stylu CSS utworzono klasę uzytkownik. Na stronie będą wyświetlane czcionką w kolorze niebieskim: p.uzytkownik { color: blue; }
A. wszystkie akapity.
B. akapitów, którym przypisano klasę uzytkownik.
C. wszystkie elementy w sekcji <body> z przypisaną klasą uzytkownik.
D. jedynie elementy tekstowe takie jak <p>, <h1>.
Odpowiedź, że paragrafy przypisane do klasy 'uzytkownik' będą miały niebieską czcionkę, jest jak najbardziej trafna. W CSS używamy kropki, żeby zdefiniować klasę, co oznacza, że styl dotyczy tylko tych elementów HTML, które mają tę klasę. Więc jeśli masz coś takiego w HTML jak <p class='uzytkownik'>, to na pewno będzie to wyświetlane z niebieską czcionką, zgodnie z Twoją regułą CSS. Takie podejście super wspiera modularność i możliwość ponownego użycia kodu, co jest naprawdę ważne w tworzeniu stron. Dzięki klasom CSS łatwo da się ogarnąć styl w różnych miejscach w kodzie, a zmieniając kolor czcionki w pliku CSS, zmiana ta natychmiast zaktualizuje wszystkie elementy z tą klasą. Przykładowo, akapit <p class='uzytkownik'> będzie miał niebieski kolor i to fajnie wpływa na spójność wizualną strony. Pamiętaj też, że klasy CSS można stosować nie tylko do akapitów, ale też do innych znaczników, co daje większą swobodę w stylizacji treści.
Pytanie 33
Aby przyznać użytkownikowi prawa do tabel w bazie danych, powinno się użyć polecenia
A. CREATE
B. SELECT
C. REVOKE
D. GRANT
Polecenie GRANT jest kluczowym elementem zarządzania uprawnieniami w systemach baz danych, takich jak MySQL, PostgreSQL czy Oracle. Umożliwia ono administratorom nadawanie określonych uprawnień użytkownikom lub rolom, co jest niezbędne do zapewnienia bezpieczeństwa danych oraz kontroli dostępu. Przykładowo, aby umożliwić użytkownikowi o nazwie 'Jan' dostęp do tabeli 'Klienci', można użyć polecenia: GRANT SELECT ON Klienci TO Jan; co przyznaje użytkownikowi prawo do odczytu danych z tej tabeli. Z perspektywy dobrych praktyk, zaleca się stosowanie minimalnych uprawnień, co oznacza, że użytkownik powinien mieć przyznane tylko te uprawnienia, które są mu niezbędne do wykonywania swoich zadań. Dzięki temu można zredukować ryzyko nieautoryzowanego dostępu do wrażliwych informacji. Dodatkowo, operacja GRANT może być stosowana w połączeniu z innymi poleceniami, takimi jak REVOKE, które służy do odbierania wcześniej nadanych uprawnień, co stanowi integralną część zarządzania bezpieczeństwem w bazach danych.
Pytanie 34
W instrukcji warunkowej w języku JavaScript należy zweryfikować sytuację, w której wartość zmiennej a mieści się w przedziale (0, 100), a wartość zmiennej b jest większa od zera. Jak można poprawnie zapisać taki warunek?
A. if (a > 0 || a < 100 11 b < 0)
B. if (a > 0 && a < 100 && b > 0)
C. if ((a > 0 && a < 100) 11 b < 0)
D. if ((a > 0 11 a < 100) && b > 0)
Odpowiedzi, które nie spełniają wymogów pytania, zawierają różne błędy logiczne i syntaktyczne, które mogą prowadzić do nieporozumień w kodzie. W pierwszej opcji użyto operatora '11', co jest błędem, ponieważ nie jest to poprawny operator w JavaScript. Prawidłowy operator to '&&', który łączy warunki logiczne. W przypadku drugiej opcji zastosowano operator '||', co oznacza logiczne 'lub', co jest nieodpowiednie, gdyż wymaga spełnienia przynajmniej jednego z warunków, co nie jest zgodne z wymaganiem pytania. Dodatkowo, warunek a < 100 powinien być połączony z a > 0 w sposób, który jednoznacznie wskazuje na przedział wartości, co nie ma miejsca w tym zapisie. W kolejnej odpowiedzi, użycie operatora '11' również jest niepoprawne, co świadczy o nieznajomości podstawowych zasad składni języka JavaScript oraz błędnym zrozumieniu operatorów logicznych. Tego typu błędy często wynikają z ustalonych nawyków programistycznych, które nie uwzględniają specyfiki języka, co prowadzi do nieprawidłowych wniosków. Aby unikać takich pomyłek, warto regularnie przeglądać dokumentację oraz praktykować pisanie kodu z zachowaniem wytycznych dotyczących standardów i dobrych praktyk programowania.
Pytanie 35
Instrukcja użytkownika aplikacji nie powinna zawierać
A. sposobu działania poszczególnych komponentów.
B. opisu instalacji programu.
C. wymagań sprzętowych.
D. opisu zastosowanych algorytmów.
Poprawnie – instrukcja użytkownika aplikacji nie powinna zawierać opisu zastosowanych algorytmów. Dokument „dla użytkownika” ma jedno główne zadanie: w prosty sposób pokazać, jak korzystać z programu, a nie jak jest on zbudowany w środku. Algorytmy, struktury danych, złożoność obliczeniowa, szczegóły implementacyjne – to jest domena dokumentacji technicznej, przeznaczonej dla programistów, architektów systemów czy osób rozwijających oprogramowanie. Z punktu widzenia zwykłego użytkownika ważne jest raczej: na jakim sprzęcie aplikacja pójdzie, jak ją zainstalować, jak uruchomić konkretną funkcję i co zrobić, gdy coś nie działa. Moim zdaniem wrzucanie do instrukcji opisów algorytmów szkodzi na dwóch poziomach. Po pierwsze, zaciemnia obraz – użytkownik musi przebijać się przez techniczne treści, których i tak nie wykorzysta, zamiast skupić się na krokach „kliknij tu, wybierz to, zapisz”. Po drugie, z punktu widzenia bezpieczeństwa i ochrony własności intelektualnej firmy, zbyt szczegółowe ujawnianie algorytmów w publicznej instrukcji nie jest najlepszą praktyką. Standardem branżowym jest rozdzielenie dokumentacji na: user guide (instrukcja użytkownika), admin guide (dla administratorów), developer/technical documentation (dla twórców i integratorów). W user guide opisujemy np. wymagania sprzętowe (system operacyjny, ilość RAM, miejsce na dysku), sposób instalacji (krok po kroku, zrzuty ekranu), oraz działanie funkcji z punktu widzenia użytkownika („ten przycisk eksportuje dane do PDF”). Natomiast algorytmy sortowania, szyfrowania, kompresji czy przetwarzania danych trafiają do dokumentów technicznych, specyfikacji lub repozytorium kodu. W praktyce, jeśli użytkownik musi znać algorytm, żeby użyć programu, to znaczy, że interfejs jest po prostu źle zaprojektowany.
Pytanie 36
Które z poniższych stwierdzeń na temat klucza głównego jest prawdziwe?
A. Jest unikalny dla danej tabeli
B. Składa się wyłącznie z jednego pola
C. W przypadku tabeli z danymi osobowymi może to być pole nazwisko
D. Może przyjmować wyłącznie wartości liczbowe
Klucz podstawowy to atrybut (lub zbiór atrybutów) w tabeli, który jednoznacznie identyfikuje każdy wiersz w tej tabeli. Jego unikalność w obrębie tabeli jest kluczowa, ponieważ pozwala na zapobieganie duplikatom i zapewnia integralność danych. Na przykład, w tabeli przechowującej informacje o klientach, kolumna z identyfikatorem klienta (np. ID klienta) powinna być kluczem podstawowym, ponieważ każdy klient musi mieć unikalny identyfikator. Standardy baz danych, takie jak model relacyjny, podkreślają znaczenie kluczy podstawowych w zapewnieniu stabilności i efektywności w przechowywaniu danych. Użycie klucza podstawowego również wpływa na wydajność operacji wyszukiwania i łączenia tabel, dlatego w projektowaniu baz danych należy starannie dobierać atrybuty, które będą pełnić tę rolę, aby spełniały wymagania unikalności oraz wydajności.
Pytanie 37
Jeżeli zmienna $x zawiera dowolną dodatnią liczbę naturalną, to przedstawiony kod źródłowy PHP ma na celu wyświetlenie:
D. liczb wprowadzanych z klawiatury, aż do momentu wprowadzenia wartości x
Kod źródłowy przedstawiony w pytaniu implementuje prostą pętlę while w języku PHP która ma za zadanie wyświetlić kolejne liczby począwszy od 0 aż do liczby mniejszej od wartości zmiennej $x. Inicjalizowana jest zmienna $licznik z wartością 0 i pętla wykonuje się tak długo jak długo $licznik jest różny od $x. W każdym przebiegu pętli zmienna $licznik jest wyświetlana, a następnie zwiększana o 1. Dzięki temu wyświetlane są wartości od 0 do x-1 co jest zgodne z drugą odpowiedzią w pytaniu. Jest to klasyczna struktura sterująca która pozwala na iterację po skończonej liczbie elementów. Takie podejście jest zgodne ze standardami pisania kodu, gdzie pętle sterowane są warunkami zależnymi od zmiennych kontrolnych. W praktyce zastosowanie takiej pętli może obejmować iterację po tablicach w celu przetwarzania danych. Ważne jest aby dobrze określić warunek zakończenia pętli by uniknąć błędów nieskończonych pętli które mogą prowadzić do przestoju aplikacji. Dla optymalizacji i czytelności kodu ważne jest też stosowanie odpowiednich nazw zmiennych co ułatwia zrozumienie ich funkcji w kodzie.
Pytanie 38
Która z definicji funkcji w języku C++ przyjmuje parametr typu zmiennoprzecinkowego i zwraca wartość typu całkowitego?
A. float fun1(int a)
B. float fun1(void a)
C. int fun1(float a)
D. void fun1(int a)
Każda z błędnych odpowiedzi ilustruje typowe nieporozumienia związane z deklaracją funkcji w języku C++. Odpowiedź 'void fun1(int a);' nie spełnia wymogów, ponieważ zwraca typ 'void', co oznacza, że funkcja nie zwraca żadnej wartości. To podejście jest właściwe, gdy chcemy wykonać operacje, które nie wymagają zwracania wyniku, ale nie odpowiada na pytanie dotyczące zwracania wartości całkowitej. W przypadku 'float fun1(int a);', chociaż funkcja poprawnie przyjmuje argument całkowity, zwraca typ 'float', co jest sprzeczne z wymaganiem zwrotu wartości całkowitej. Kolejna odpowiedź 'float fun1(void a);' zawiera syntaktyczny błąd, ponieważ typ 'void' nie może być użyty jako typ parametru, co prowadzi do błędów kompilacji. W języku C++ każdy parametr musi mieć określony typ, a użycie 'void' jako typu parametru jest niepoprawne. Te nieprawidłowe odpowiedzi wskazują na brak zrozumienia podstawowych zasad typowania w C++, co jest kluczowe w kontekście projektowania funkcji. Istotne jest, aby przy tworzeniu funkcji dobrze zrozumieć, jakie typy danych są akceptowane i jakie wartości są oczekiwane jako wynik, aby uniknąć błędów w logice programu oraz poprawić jego wydajność i czytelność.
Pytanie 39
W języku CSS określono formatowanie znacznika h1 według wzoru. Zakładając, że żadne inne formatowanie nie jest dodane do znacznika h1, wskaż sposób formatowania tego znacznika
A. B
B. C
C. D
D. A
Formatowanie znacznika h1, określone w podanym kodzie CSS, wprowadza kilka charakterystycznych cech stylistycznych. Przede wszystkim, zastosowanie 'font-style: oblique;' zmienia wygląd tekstu, nadając mu ukośny styl. To oznacza, że tekst będzie wyświetlany w wyraźnie przechylonej formie, co jest często używane do podkreślenia ważnych elementów. Dodatkowo, 'font-variant: small-caps;' odpowiedzialne jest za przekształcenie małych liter w małe kapitałki, co nadaje tekstowi elegancki i formalny wygląd. Taki zabieg jest często wykorzystywany w tytułach lub nagłówkach, aby wyróżnić je wśród pozostałego tekstu. Ostatni element, 'text-align: right;', wyrównuje tekst do prawej krawędzi kontenera, co jest mniej powszechnie stosowane w porównaniu do wyrównania do lewej lub wyśrodkowanego, ale może być użyteczne w specyficznych układach strony. W przypadku, gdyby były dodatkowe style CSS przypisane do tego znacznika, mogłyby one wpłynąć na ostateczny wygląd, jednak w tym przypadku zakładamy, że są to jedyne zastosowane style. Standardy CSS jasno określają, jak różne właściwości mogą być używane do stylizacji elementów HTML, co czyni je niezwykle potężnym narzędziem w tworzeniu estetycznych i funkcjonalnych stron internetowych.
Pytanie 40
W programie do edycji grafiki rastrowej, aby skoncentrować się na wybranej części obrazu, nie wpływając na pozostałe jego fragmenty, można zastosować
A. odwrócenie
B. przycinanie
C. zmianę rozmiaru
D. warstwy
Zastosowanie skalowania w edytorze grafiki rastrowej polega na zmianie rozmiaru obrazu, co wpływa na wszystkie jego elementy. Przykładowo, jeśli zdecydujemy się na skalowanie, wszystkie obiekty na obrazie zostaną powiększone lub pomniejszone w równym stopniu, co nie pozwala na selektywne modyfikacje. Inwersja, z kolei, to proces zmiany kolorów pikseli w obrazie na ich przeciwieństwa, co również nie umożliwia pracy na wybranej części obrazu bez zmiany innych elementów. Ponadto kadrowanie, które polega na przycinaniu części obrazu, również nie dostarcza narzędzi do edytowania wybranych elementów bez wpływu na resztę kompozycji. Takie podejścia są często mylnie postrzegane jako odpowiednie metody do pracy z grafiką rastrową, podczas gdy w rzeczywistości nie oferują elastyczności potrzebnej do profesjonalnej edycji. Nieprawidłowe wnioski mogą prowadzić do frustracji w trakcie edycji, zwłaszcza w bardziej złożonych projektach, gdzie precyzyjna kontrola nad elementami obrazu jest kluczowa. Dlatego istotne jest zrozumienie roli warstw jako jedynego narzędzia, które umożliwia niezależne zarządzanie elementami grafiki rastrowej.
Strona wykorzystuje pliki cookies do poprawy doświadczenia użytkownika oraz analizy ruchu. Szczegóły
Polityka plików cookies
Czym są pliki cookies?
Cookies to małe pliki tekstowe, które są zapisywane na urządzeniu użytkownika podczas przeglądania stron internetowych. Służą one do zapamiętywania preferencji, śledzenia zachowań użytkowników oraz poprawy funkcjonalności serwisu.
Jakie cookies wykorzystujemy?
Niezbędne cookies - konieczne do prawidłowego działania strony
Funkcjonalne cookies - umożliwiające zapamiętanie wybranych ustawień (np. wybrany motyw)
Analityczne cookies - pozwalające zbierać informacje o sposobie korzystania ze strony
Jak długo przechowujemy cookies?
Pliki cookies wykorzystywane w naszym serwisie mogą być sesyjne (usuwane po zamknięciu przeglądarki) lub stałe (pozostają na urządzeniu przez określony czas).
Jak zarządzać cookies?
Możesz zarządzać ustawieniami plików cookies w swojej przeglądarce internetowej. Większość przeglądarek domyślnie dopuszcza przechowywanie plików cookies, ale możliwe jest również całkowite zablokowanie tych plików lub usunięcie wybranych z nich.