Pytanie 1
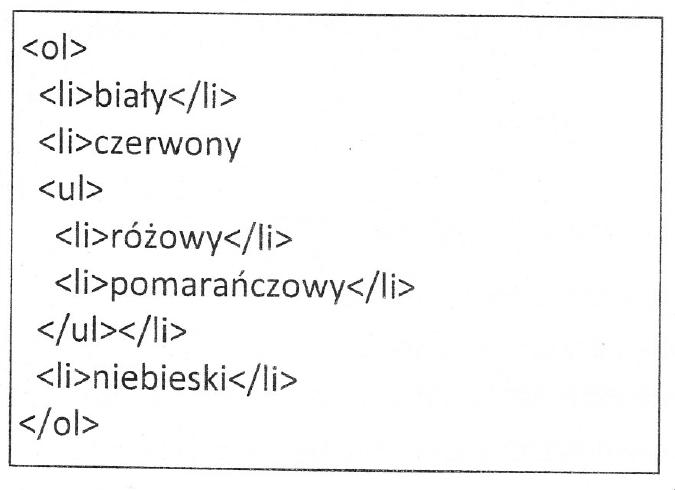
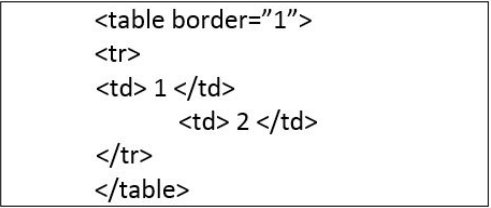
Zaprezentowano tabelę stworzoną przy użyciu kodu HTML, bez zastosowania stylów CSS. Która część kodu HTML odnosi się do pierwszego wiersza tabeli?

A. Rys. B
B. Rys. C
C. Rys. A
D. Rys. D
Znaczniki HTML używane w konstrukcji tabel muszą być wybierane z uwzględnieniem ich przeznaczenia i semantycznego znaczenia. W przypadku budowy pierwszego wiersza tabeli, który pełni rolę nagłówka, kluczowe jest wykorzystanie odpowiednich znaczników, takich jak <th>. Wybór znaczników <td> w pierwszym wierszu, nawet jeśli zawierają one tekst pasujący do nagłówków, jest błędny, ponieważ <td> oznacza komórki danych, a nie nagłówki. Tego typu błędy mogą prowadzić do niejednoznacznej interpretacji struktury tabeli przez technologie wspomagające, jak czytniki ekranowe, co jest sprzeczne z wytycznymi dotyczącymi dostępności. Dodatkowo, korzystanie z tagów niewłaściwie zamieniających semantykę (np. <i> lub <center> wewnątrz <td>) nie tylko nie spełnia standardów estetycznych i funkcjonalnych, ale także zwiększa techniczne zadłużenie projektu. Brak poprawnego stosowania znaczników nagłówka (<th>) może utrudniać zrozumienie danych przez użytkowników oraz wpływać negatywnie na użyteczność strony. Poprawne zrozumienie i stosowanie semantycznych możliwości HTML jest fundamentem tworzenia dostępnych i efektywnych stron internetowych co ma kluczowe znaczenie w kontekście profesjonalnego podejścia do projektowania interfejsów użytkownika i architektury informacji na stronach internetowych.