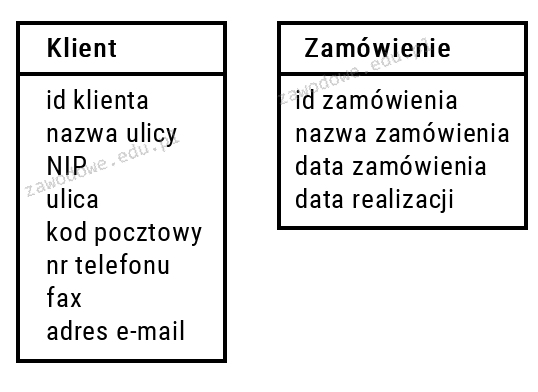
Pytanie 1
W języku SQL instrukcja INSERT INTO
A. tworzy nową tabelę
B. zmienia rekordy na zadaną wartość
C. dodaje kolumny do istniejącej tabeli
D. wprowadza dane do tabeli
Polecenie INSERT INTO w języku SQL jest używane do dodawania nowych danych do tabeli w bazie danych. Jego podstawowa składnia to: INSERT INTO nazwa_tabeli (kolumna1, kolumna2, ...) VALUES (wartość1, wartość2, ...). Dzięki temu poleceniu użytkownicy mogą wprowadzać nowe rekordy, co jest kluczowe w zarządzaniu danymi w relacyjnych bazach danych. Przykładowo, jeżeli mamy tabelę 'użytkownicy' z kolumnami 'imie', 'nazwisko' i 'wiek', możemy dodać nowego użytkownika za pomocą: INSERT INTO użytkownicy (imie, nazwisko, wiek) VALUES ('Jan', 'Kowalski', 30). Warto zauważyć, że polecenie to może być używane w kontekście transakcji, co pozwala na zachowanie integralności danych. Standard SQL, na którym opiera się wiele systemów zarządzania bazami danych, definiuje to polecenie jako fundamentalne w operacjach DML (Data Manipulation Language), co czyni je niezbędnym w każdej aplikacji, która wymaga wprowadzania danych do bazy.