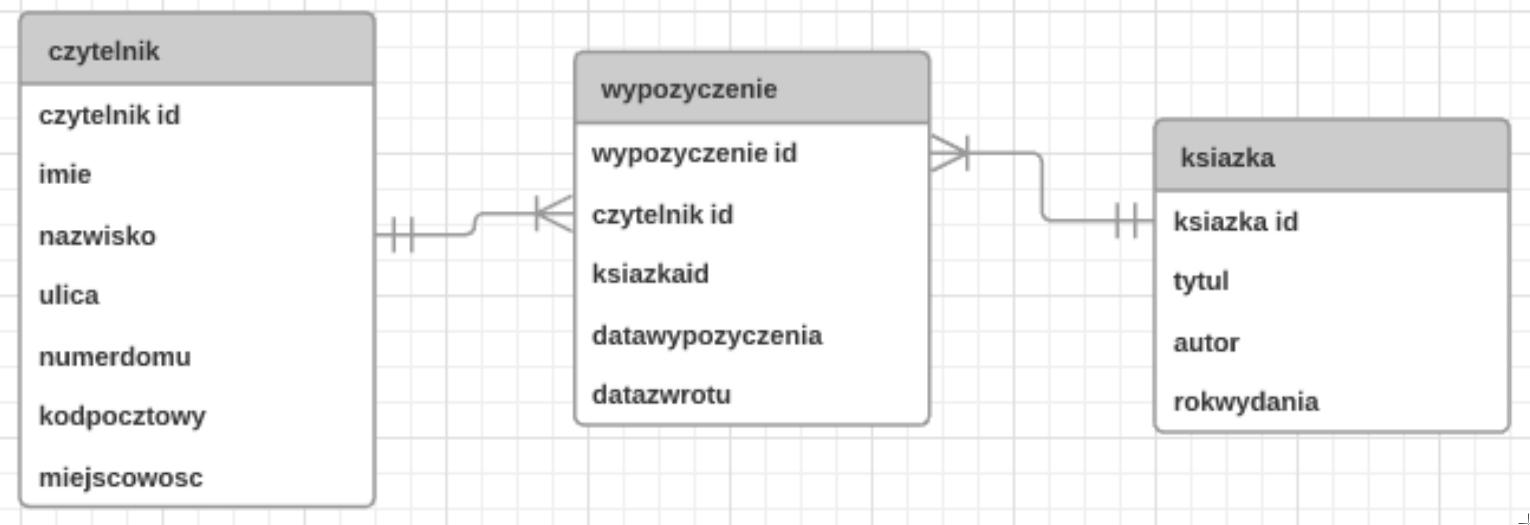
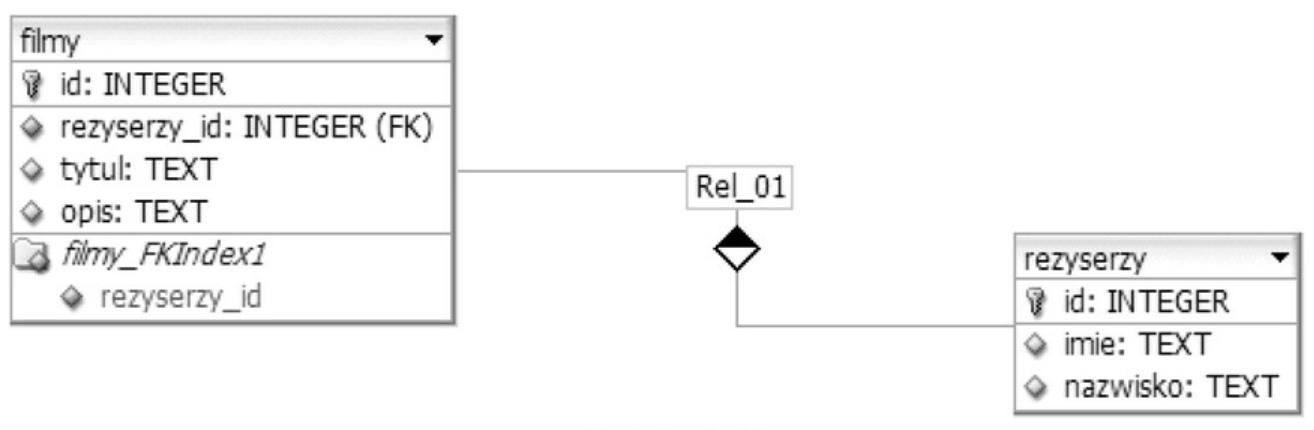
Pytanie 1
W zamieszczonym kodzie PHP, zamiast znaków zapytania powinien być wyświetlony komunikat:
$x = mysql_query('SELECT * FROM mieszkancy');
if (!$x)
echo '??????????????????????';A. Błąd w trakcie przetwarzania zapytania
B. Niepoprawna nazwa bazy danych
C. Zapytanie zostało poprawnie przetworzone
D. Niepoprawne hasło do bazy danych
W przedstawionym kodzie PHP, komunikat "??????????????????????" powinien wskazywać na błąd przetwarzania zapytania SQL. Kiedy wynik funkcji mysql_query() jest równy fałszowi (false), oznacza to, że zapytanie nie mogło zostać poprawnie wykonane. Może to być spowodowane różnymi czynnikami, takimi jak błędy w składni zapytania, problemy z połączeniem z bazą danych, lub nieprawidłowe tabele. W tym przypadku, dobrym podejściem jest użycie funkcji mysql_error() w celu uzyskania bardziej szczegółowych informacji na temat natury błędu. Przykład poprawnego kodu mógłby wyglądać tak: <p>$x = mysql_query('SELECT * FROM mieszkancy');<br>If (!$x) {<br>echo mysql_error();<br>}</p> Używanie tej metody pomaga w diagnostyce problemu i pozwala na szybsze jego rozwiązanie. Znalezienie i naprawienie błędów w zapytaniach SQL jest kluczowe w pracy z bazami danych, szczególnie w kontekście aplikacji internetowych, które muszą być niezawodne i efektywne.