Pytanie 1
Najprostszy sposób przekształcenia obiektu oznaczonego cyfrą 1 w obiekt oznaczony cyfrą 2 to
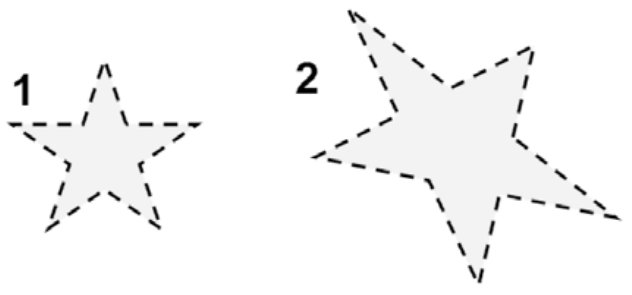
A. narysowanie docelowego obiektu
B. zmiana warstwy obiektu
C. geometryczne transformowanie obiektu
D. animowanie obiektu
Geometria transformacji to niezwykle ważne pojęcie w dziedzinie grafiki komputerowej i projektowania. Polega na zmianie kształtu obiektu za pomocą operacji takich jak skalowanie, obracanie, przesuwanie czy odkształcanie. W kontekście pytania, geometria transformacji umożliwia przekształcenie obiektu oznaczonego cyfrą 1 w obiekt oznaczony cyfrą 2 poprzez zmianę jego kształtu i wielkości. Praktyczne zastosowanie transformacji geometrycznych obejmuje m.in. skalowanie w celu dostosowania rozmiarów obiektów do różnych nośników lub kontekstu wyświetlania. Obracanie jest używane do orientacji obiektów w przestrzeni, co jest niezwykle przydatne w modelowaniu 3D czy animacjach. Dobre praktyki projektowania graficznego zalecają korzystanie z transformacji geometrycznych, aby uzyskać spójną i estetyczną kompozycję. Standardy branżowe często definiują konkretne algorytmy i formaty danych dla transformacji, jak na przykład macierze przekształceń w grafice trójwymiarowej. Zrozumienie i umiejętne zastosowanie tych pojęć pozwala na efektywne tworzenie złożonych struktur wizualnych oraz interaktywnych aplikacji.