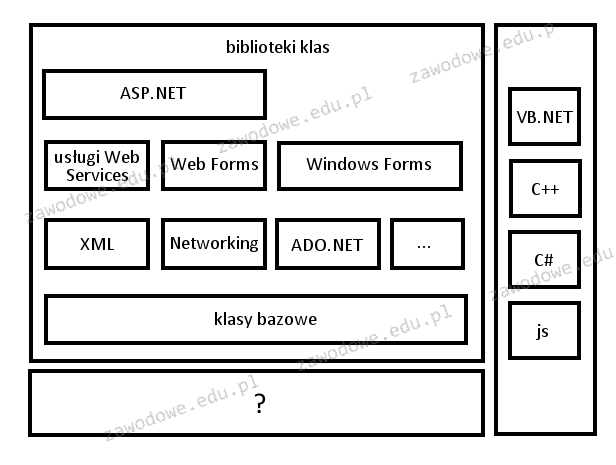
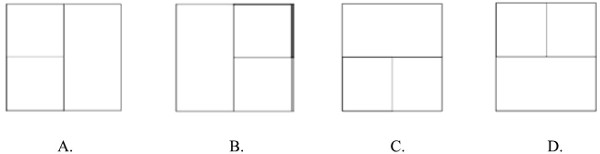
Pytanie 1
Jak wygląda instrukcja przypisania wartości do elementu tablicy w języku JavaScript względem tablicy? ```Tablica['technik'] = 'informatyk';```
A. numerycznej
B. asocjacyjnej
C. wielowymiarowej
D. statycznej
W języku JavaScript tablice mogą być traktowane jako obiekty, a więc wykazują cechy struktur asocjacyjnych. Przypisując wartość do tablicy za pomocą notacji z nawiasami kwadratowymi, jak w przykładzie 'Tablica[\'technik\'] = \'informatyk\';', tworzymy nowy element o kluczu 'technik', co jest charakterystyczne dla obiektów asocjacyjnych. W JavaScript tablice są dynamiczne, co oznacza, że możemy dodawać elementy w dowolny sposób, a ich rozmiar nie jest ustalony z góry. Standard ECMAScript definiuje tablice jako obiekty, gdzie klucze są indeksami liczb całkowitych, ale można również używać stringów jako kluczy, co czyni tablice asocjacyjnymi. Przykładem może być obiekt, który przechowuje różne informacje, a elementy są dostępne zarówno za pomocą indeksów numerycznych, jak i stringów. Warto zaznaczyć, że użycie tablicy jako obiektu asocjacyjnego może być praktyczne w wielu zastosowaniach, np. w przechowywaniu konfiguracji czy zestawów danych. Dobrą praktyką jest jednak ograniczać użycie takich technik dla przejrzystości kodu."