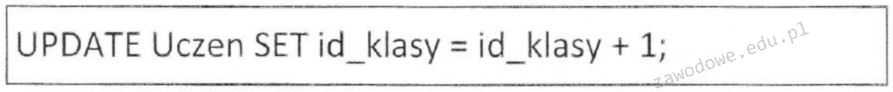Pytanie 1
Instrukcja zapisana w SQL, przedstawiona poniżej, ilustruje kwerendę:
UPDATE katalog SET katalog.cena = [cena]*1.1;
A. krzyżowej
B. aktualizującej
C. usuwającej
D. dołączającej
Odpowiedź "aktualizującej" jest prawidłowa, ponieważ instrukcja SQL, którą przedstawiono, służy do modyfikacji istniejących danych w tabeli. Kwerenda ta używa polecenia UPDATE, które jest standardowym poleceniem w SQL do zmiany wartości w jednej lub wielu kolumnach w wybranych wierszach tabeli. W tym przypadku, kwerenda zwiększa wartość ceny o 10% dla wszystkich rekordów w tabeli 'katalog'. Takie operacje są powszechnie stosowane w zarządzaniu bazami danych, szczególnie w kontekście aktualizacji cen produktów, co jest kluczowe w handlu elektronicznym i zarządzaniu zapasami. Ważne jest również, aby przy każdej aktualizacji danych uwzględnić warunki, jeśli zmiana ma dotyczyć tylko określonych wierszy, co można osiągnąć poprzez dodanie klauzuli WHERE. Ponadto, dobrym nawykiem jest zawsze tworzenie kopii zapasowych danych przed przeprowadzeniem masowych aktualizacji, aby zminimalizować ryzyko utraty informacji.