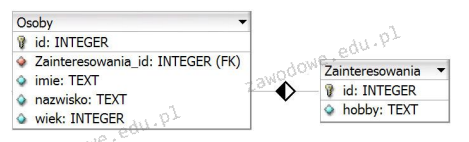
Pytanie 1
Która wartość tekstowa nie pasuje do podanego w ramce wzorca wyrażenia regularnego?
(([A-ZŁŻ][a-ząęóżźćńłś]{2,})(-[A-ZŁŻ][a-ząęóżźćńłś]{2,})?)
A. Jelenia Góra
B. Kowalski
C. Nowakowska-Kowalska
D. Kasprowicza
Wszystkie pozostałe wartości tekstowe, takie jak Kowalski, Kasprowicza oraz Nowakowska-Kowalska, spełniają wymagania określone przez wzorzec wyrażenia regularnego. Kowalski to przykład pojedynczego nazwiska, które zaczyna się od dużej litery oraz zawiera wystarczającą liczbę małych liter, co czyni je poprawnym. Kasprowicza również jest poprawne, gdyż zawiera dużą literę na początku, a następnie dwa znaki małe, co jest zgodne z wymaganiami. Dodatkowo, oba nazwiska nie zawierają spacji ani innych znaków, które mogłyby zakłócić strukturę wyrażenia regularnego. Nowakowska-Kowalska jest przykładem podwójnego nazwiska, które jest również zgodne z wzorcem, ponieważ składa się z dwóch części, oddzielonych znakiem '-' i każda z nich zaczyna się od dużej litery, a następnie zawiera co najmniej dwa znaki małe. Obie części nazwiska spełniają wymagania dotyczące polskich znaków diakrytycznych oraz ilości liter, dlatego są one uznawane za poprawne. W związku z tym, nieprawidłowa odpowiedź 'Jelenia Góra' wyróżnia się jako jedyna, która narusza zasady ustalone przez wzorzec.