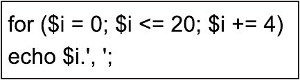Pytanie 1
Liczba 0x142, przedstawiona w skrypcie JavaScript, jest zapisywana w postaci
A. dwójkowej
B. szesnastkowej
C. dziesiętnej
D. ósemkowej
Odpowiedzi sugerujące, że liczba 0x142 jest zapisana w systemie dziesiętnym, dwójkowym lub ósemkowym, są błędne z kilku powodów. System dziesiętny, bazujący na podstawie 10, używa cyfr od 0 do 9. Gdyby 0x142 byłoby w systemie dziesiętnym, nie miałby prefiksu '0x', a jego wartość wynosiłaby 322, co jest całkowicie inną reprezentacją. Z kolei system dwójkowy, znany również jako binarny, używa tylko dwóch cyfr: 0 i 1. Liczba 0x142 w systemie binarnym wynosi 101000010, co jest zupełnie inną formą niż przedstawienie szesnastkowe. Na koniec, system ósemkowy, mający podstawę 8, obejmuje cyfry od 0 do 7. Aby wyrazić 0x142 w systemie ósemkowym, należałoby najpierw przekonwertować ją na dziesiętną, co dałoby 322, a następnie na ósemkowy, co dawałoby 502. Tak więc żadna z tych odpowiedzi nie jest poprawna, ponieważ 0x142 jest jednoznacznie zapisane w systemie szesnastkowym.