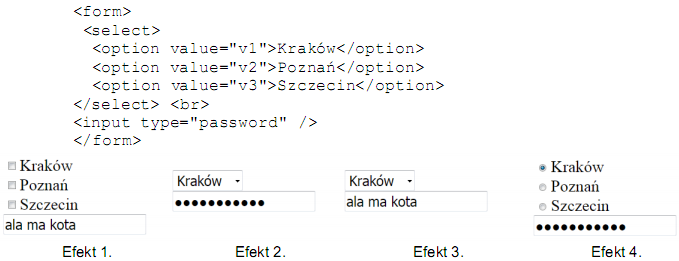
Pytanie 1
Portal internetowy dysponuje bardzo złożonym systemem stylów, który obejmuje style zewnętrzne, wewnętrzne oraz lokalne. Jak można zagwarantować, że określona cecha zdefiniowana w zewnętrznym stylu jest zawsze stosowana do elementu HTML, niezależnie od bardziej priorytetowych stylów?
A. przy pomocy pseudoelementu ::after
B. jako selektor potomka
C. jako pseudoklasę :active
D. przy pomocy reguły !important
Odpowiedź, że cechę opisaną w zewnętrznym stylu należy zdefiniować przy pomocy reguły !important jest poprawna. Reguła !important w CSS jest używana do nadania określonej właściwości najwyższego priorytetu. Oznacza to, że nawet jeśli inne reguły CSS mają wyższy specyficzność lub są zdefiniowane później, właściwość oznaczona jako !important zostanie zastosowana. Przykład zastosowania to sytuacja, gdy styl globalny dla elementu przyjmuje kolor tła, ale chcemy, aby dany element zawsze miał czerwony kolor tła, niezależnie od innych reguł. W takim przypadku możemy zdefiniować ten styl jako: `.example { background-color: red !important; }`. Ważne jest, aby stosować !important z rozwagą, ponieważ może to prowadzić do trudności w utrzymaniu kodu oraz nadpisywaniu stylów w nieprzewidywalny sposób. Dobrym podejściem jest najpierw spróbować zwiększyć specyficzność selektora, a dopiero potem, w nagłych wypadkach, używać !important, aby unikać problemów z dziedziczeniem stylów.