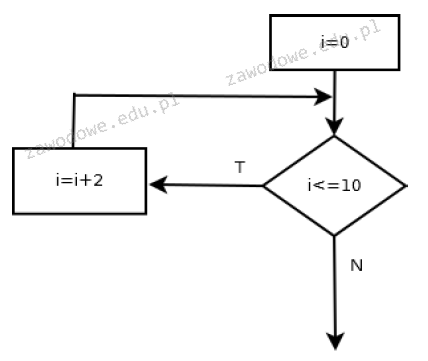
Pytanie 1
W języku HTML aby zdefiniować słowa kluczowe strony, należy użyć zapisu
A. <meta name = "keywords" = "psy, koty, gryzonie">
B. <meta name = "description" content = "psy, koty, gryzonie">
C. <meta keywords = "psy, koty, gryzonie">
D. <meta name = "keywords" content = "psy, koty, gryzonie">
Poprawna odpowiedź to <meta name = "keywords" content = "psy, koty, gryzonie">, ponieważ jest to właściwy sposób definiowania słów kluczowych w sekcji <head> dokumentu HTML. Element <meta> służy do dostarczania metadanych o stronie internetowej, a atrybut 'name' określa, jakie informacje są zawarte w danym elemencie. W przypadku 'keywords', atrybut 'content' z kolei zawiera listę słów kluczowych, które są związane z treścią strony. Chociaż znaczenie słów kluczowych w SEO zmienia się, wciąż są one używane przez niektóre wyszukiwarki do kategoryzowania zawartości strony. Przykładowo, jeśli strona dotyczy zwierząt domowych, użycie fraz takich jak 'psy', 'koty', czy 'gryzonie' w atrybucie 'content' może pomóc w poprawie widoczności w wynikach wyszukiwania. Dobrą praktyką jest, aby słowa kluczowe były specyficzne, związane z tematyką strony i nie przekraczały rozsądnej liczby, aby nie wprowadzać w błąd algorytmy wyszukiwarek. Używanie odpowiednich metatagów to kluczowy element optymalizacji SEO.