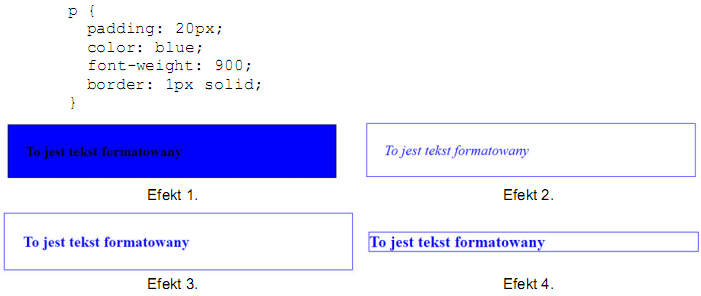
Pytanie 1
W jakim standardzie języka hipertekstowego wprowadzono do składni znaczniki sekcji <footer>, <header>, <nav>?
A. HTML5
B. HTML4
C. XHTML1.0
D. XHTML 2.0
Tak, znaczników <footer>, <header> i <nav> zaczęto używać w HTML5, który zadebiutował w październiku 2014 roku. To jest ciekawe, bo HTML5 wprowadził sporo nowych semantycznych elementów, które pomagają w lepszej organizacji dokumentów HTML. Dzięki nim, przeglądarki i roboty wyszukiwarek mogą lepiej zrozumieć strukturę stron. Na przykład, <header> to nagłówek strony lub sekcji, <nav> tworzy menu nawigacyjne, a <footer> to stopka. Myślę, że to super sprawa, bo poprawia dostępność strony i jej SEO, bo tak naprawdę pomaga wyszukiwarkom w lepszym indeksowaniu treści, co może prowadzić do lepszych wyników w wyszukiwarkach. Dodatkowo, HTML5 ma też inne ciekawe nowinki, jak wsparcie dla multimediów, lokalne przechowywanie danych, a także lepszą kompatybilność z aplikacjami mobilnymi, więc zdecydowanie warto go wykorzystywać do budowy stron internetowych.