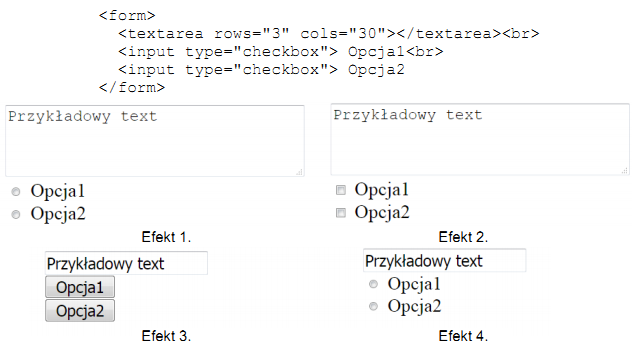
Pytanie 1
Zapis CSS w postaci: ```ul{ list-style-image:url('rys.gif');}``` spowoduje, że na stronie internetowej
A. punktorem nienumerowanej listy stanie się rys.gif
B. każdy element listy zyska indywidualne tło pochodzące z grafiki rys.gif
C. rysunek rys.gif zostanie wyświetlony jako punkt listy nienumerowanej
D. rys.gif będzie służyć jako tło dla nienumerowanej listy
Podane odpowiedzi, które sugerują alternatywne interpretacje, nie są zgodne z rzeczywistością techniczną CSS. Przede wszystkim, twierdzenie, że rys.gif będzie stanowił ramkę dla listy nienumerowanej, jest błędne, ponieważ właściwość 'list-style-image' nie ma wpływu na obramowanie listy, a jedynie na sposób, w jaki są wyświetlane punkty listy. CSS do definiowania obramowań używa innych właściwości, takich jak 'border'. Z kolei stwierdzenie o wyświetlaniu rysunku rys.gif jako tł listy nienumerowanej jest mylące; to nie jest tło całej listy, ale pojedyncze punkty, które zastępują tradycyjne znaczniki. Ostatnia niepoprawna odpowiedź sugeruje, że każdy punkt listy miałby osobne tło pobrane z grafiki rys.gif. Jest to błędne, ponieważ definicja tła w CSS dotyczy całego elementu, a nie poszczególnych znaczników. Aby uzyskać różne tła dla elementów listy, należałoby użyć oddzielnych właściwości CSS dla każdego z nich zamiast 'list-style-image'. Dlatego wszystkie te odpowiedzi nie uwzględniają zasadniczej funkcji właściwości CSS, jaką jest kontrolowanie wizualnych markerów listy.