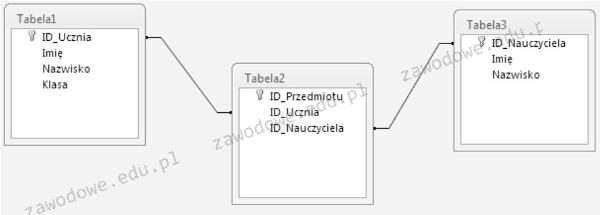
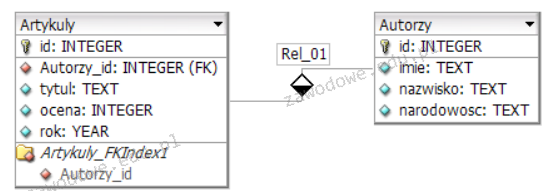
Pytanie 1
Aby skorzystać z relacji w zapytaniu, trzeba użyć słowa kluczowego
A. UNION
B. JOIN
C. GROUP BY
D. IN
Wybór słów kluczowych takich jak UNION, IN oraz GROUP BY w kontekście łączenia danych z różnych tabel jest nieprawidłowy i opiera się na błędnym zrozumieniu funkcji tych instrukcji. UNION jest używane do łączenia wyników dwóch lub więcej zapytań, ale nie łączy danych z różnych tabel na podstawie relacji. Umożliwia ono zestawienie wyników, które mają tę samą strukturę, co oznacza, że wszystkie zapytania muszą zwracać tę samą liczbę kolumn i odpowiadające im typy danych. IN z kolei służy do porównywania wartości w jednej kolumnie z zestawem wartości, ale nie operuje na relacjach między tabelami. Ta instrukcja jest bardziej przydatna w filtracji wyników, a nie w ich łączeniu. GROUP BY jest używane do grupowania wyników na podstawie określonych kolumn, co jest niezbędne w przypadku agregacji danych, ale również nie odnosi się bezpośrednio do łączenia tabel. Zrozumienie tych różnic jest kluczowe, aby unikać typowych błędów w projektowaniu zapytań SQL. Zamiast tego, należy skupić się na technikach łączenia danych przy użyciu JOIN, co jest zgodne z najlepszymi praktykami w zakresie zarządzania danymi w systemach baz danych.