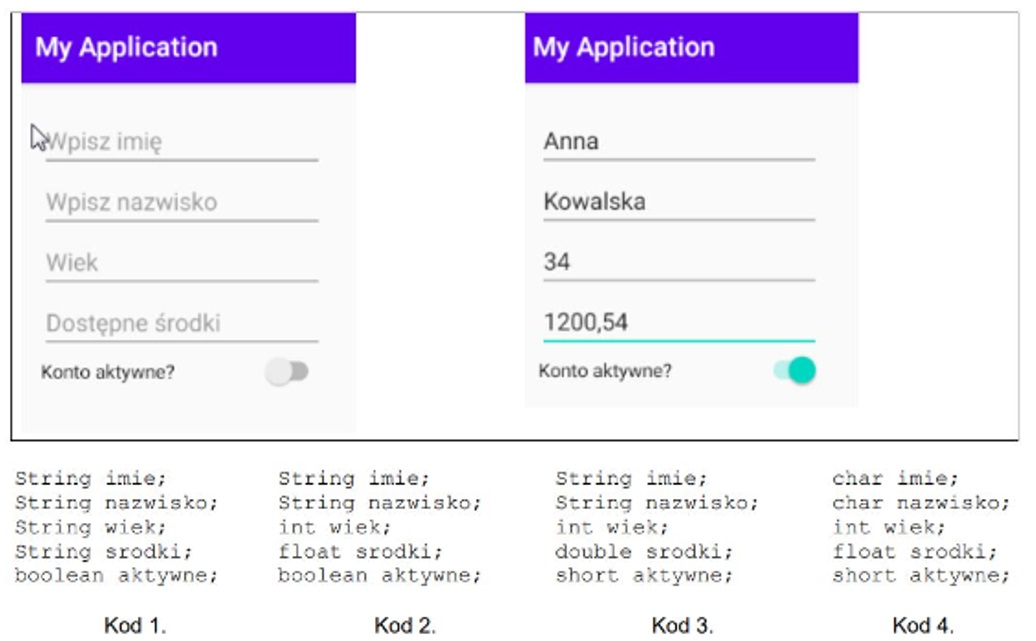
Pytanie 1
Celem zastosowania wzorca Obserwator w tworzeniu aplikacji WEB jest:
A. informowanie obiektów o modyfikacji stanu innych obiektów
B. monitorowanie działań użytkownika oraz generowanie wyjątków
C. zarządzanie funkcjami synchronicznymi w kodzie aplikacji
D. dostosowanie interfejsu użytkownika do różnych kategorii użytkowników
Często można się pomylić, próbując „wymyślić” jakąś funkcjonalność, którą może realizować wzorzec Obserwator w aplikacji webowej. Jednak nie każda aktywność związana ze zmianami w systemie czy komunikacją między komponentami to domena właśnie tego wzorca. Z mojego doświadczenia, widzę że wiele osób myli obserwatora z mechanizmami monitorującymi zachowanie użytkownika, jak narzędzia do śledzenia kliknięć czy generowania wyjątków w reakcji na nietypowe akcje – tymczasem Obserwator nie służy do analityki lub obsługi logiki wyjątków. To raczej narzędzie do powiadamiania powiązanych obiektów o zmianach, które zachodzą w jednym z nich. Spotkałem się także z opinią, że wzorzec ten zarządza funkcjami synchronicznymi. W praktyce nie ma on nic wspólnego z zarządzaniem synchronicznością czy asynchronicznością kodu – sam jest neutralny względem tych aspektów. Synchroniczność lub asynchroniczność zależy raczej od implementacji (np. Promises, async/await, event loop), a nie od samego wzorca Obserwator. Jeszcze inny częsty błąd to utożsamianie tego wzorca z mechanizmami dostosowującymi interfejs użytkownika do różnych profili użytkowników. To już bardziej domena wzorców strategii, kompozycji lub nawet prostych warunków w kodzie. W skrócie: Obserwator to taki „kurier”, który informuje zainteresowanych, gdy coś się zmienia – i tylko tyle. Jak dla mnie, zrozumienie tej granicy pomaga uniknąć niepotrzebnych komplikacji w projektowaniu architektury aplikacji webowych.