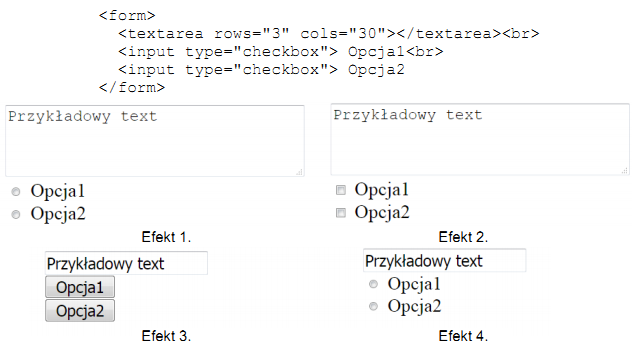
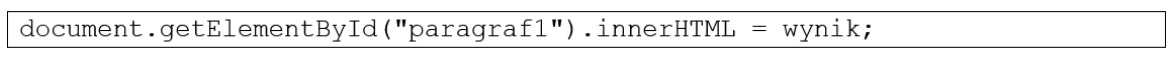Pytanie 1
Jakie jest zadanie funkcji przedstawionej w języku JavaScript?
function fun1(a, b) {
if (a % 2 != 0) a++;
for (n = a; n <= b; n+=2)
document.write(n);
}A. sprawdzenie, czy liczba a jest nieparzysta; w przypadku potwierdzenia, wypisanie jej
B. wypisanie liczb parzystych z zakresu od a do b
C. zwrócenie wartości liczb parzystych od a do b
D. wypisanie wszystkich liczb z zakresu od a do b
Odpowiedź "wypisanie liczb parzystych z przedziału od a do b" jest prawidłowa, ponieważ funkcja fun1(a, b) w języku JavaScript ma na celu wyświetlenie wszystkich liczb parzystych w zdefiniowanym zakresie. Funkcja najpierw sprawdza, czy liczba a jest nieparzysta; jeśli tak, to zwiększa ją o 1, co zapewnia, że zaczynamy od najbliższej liczby parzystej. Następnie, za pomocą pętli for, iteruje przez liczby od a do b, zwiększając n o 2 w każdej iteracji. Dzięki temu wypisujemy tylko liczby parzyste. Przykładowo, jeśli a = 3 i b = 9, to funkcja zacznie od 4 i wypisze 4, 6, i 8. Tego typu funkcje są przydatne w różnych kontekstach programistycznych, takich jak generowanie sekwencji liczb dla algorytmów matematycznych, generowanie danych testowych czy też przy pracy z interfejsami użytkownika, gdzie występują interwały liczbowe. Dobrą praktyką jest zawsze jasno określać zakres przetwarzanych danych, co ta funkcja realizuje, zapewniając, że wyniki są zgodne z oczekiwaniami użytkownika.