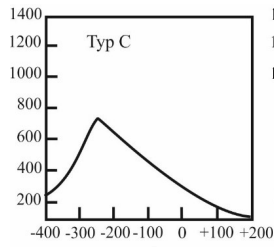
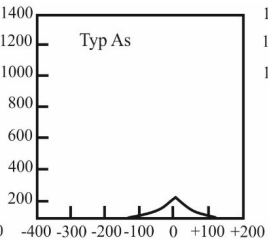
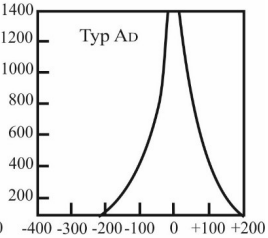
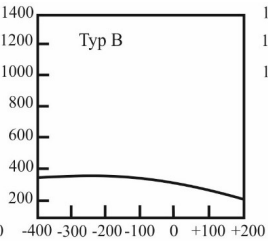
Pytanie 1
Pobierając odlew w celu wykonania aparatu głęboko wewnątrzkanałowego, protetyk powinien umieścić tampon
A. za pierwszym zakrętem i dokładnie wypełnić obrąbek masą otoplastyczną.
B. za drugim zakrętem i dokładnie wypełnić kanał słuchowy zewnętrzny masą otoplastyczną.
C. za pierwszym zakrętem i dokładnie wypełnić kanał słuchowy zewnętrzny masą otoplastyczną.
D. za drugim zakrętem i dokładnie wypełnić czółenko masą otoplastyczną.
Prawidłowe pobranie odlewu pod aparat głęboko wewnątrzkanałowy wymaga umieszczenia tamponu za drugim zakrętem przewodu słuchowego zewnętrznego i bardzo dokładnego wypełnienia masą otoplastyczną całego kanału, aż do tamponu. Drugi zakręt to granica bezpieczeństwa: z jednej strony chronimy błonę bębenkową przed kontaktem z masą, z drugiej uzyskujemy maksymalną długość i stabilizację przyszłego aparatu CIC/IIC. Dzięki temu aparat będzie głęboko osadzony, lepiej uszczelniony akustycznie, mniej widoczny i zwykle z mniejszym efektem okluzji. W praktyce protetyk po wstępnej otoskopii dobiera odpowiedni rozmiar tamponu z waty lub gąbki, umieszcza go delikatnie za drugim zakrętem (często z użyciem sondy z haczykiem), kontroluje położenie otoskopem i dopiero wtedy wprowadza masę otoplastyczną pod niewielkim ciśnieniem, bez pęcherzyków powietrza. Z mojego doświadczenia to właśnie staranne dociśnięcie masy w rejonie drugiego zakrętu i cieśni kanału robi największą różnicę w jakości dopasowania wkładki czy obudowy IIC – mniej sprzężeń zwrotnych, lepszy komfort i stabilność przy żuciu czy mówieniu. Takie postępowanie jest zgodne z typowymi wytycznymi producentów mas otoplastycznych i dobrą praktyką kliniczną w otoplastyce: głęboki, ale kontrolowany odlew, z pełnym odwzorowaniem kształtu przewodu słuchowego zewnętrznego aż do poziomu drugiego zakrętu, bez „dziur” i bez ryzyka podrażnienia błony bębenkowej.