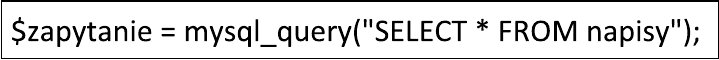Pytanie 1
W przedstawionym kodzie PHP w miejscu kropek powinno zostać umieszczone polecenie
| $zapytanie = mysqli_query($db, "SELECT imie, nazwisko FROM uzytkownik"); $ile = mysqli_num_rows($zapytanie); for ($i = 0; $i < $ile; $i++) { $wiersz = ……………………………….; echo "$wiersz[0] $wiersz[1]"; } |
A. mysqli_free_result($zapytanie);
B. mysqli_query($zapytanie);
C. mysqli_num_fields($zapytanie);
D. mysqli_fetch_row($zapytanie);
W kontekście przedstawionego kodu PHP, prawidłowe uzupełnienie wiersza poleceń to użycie funkcji mysqli_fetch_row($zapytanie). Funkcja ta pobiera jeden wiersz z zestawu wyników zapytania jako tablicę indeksowaną numerycznie. Jest to istotny krok w procesie przetwarzania danych z bazy danych, ponieważ po wykonaniu zapytania SQL, dane muszą być odpowiednio odczytane, aby można je było wykorzystać w aplikacji. Przykładowo, po wykonaniu zapytania, możemy mieć wiele wierszy danych, a mysqli_fetch_row pozwala na iteracyjne pobieranie każdego z nich. W praktyce, stosując tę funkcję w pętli, możemy w prosty sposób zbudować listę lub tabelę, wyświetlając imię i nazwisko każdego użytkownika. Warto również pamiętać, że przy pracy z bazami danych ważne jest, aby uważnie monitorować proces pobierania danych, by uniknąć problemów z pamięcią, a także aby zwolnić zasoby po zakończeniu operacji. W związku z tym, standardową praktyką jest również stosowanie mysqli_free_result($zapytanie) po zakończeniu pracy z danymi, co pozwala na efektywne zarządzanie pamięcią.