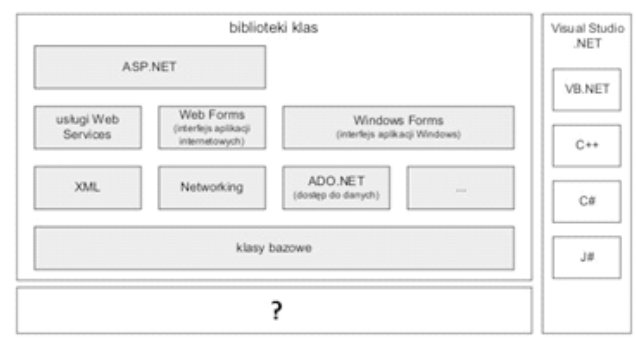
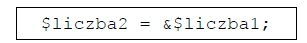Pytanie 1
W języku JavaScript trzeba zapisać warunek, który będzie prawdziwy, gdy zmienna a będzie jakąkolwiek liczbą naturalną dodatnią (bez 0) lub zmienna b przyjmie wartość z zamkniętego przedziału od 10 do 100. Wyrażenie logiczne w tym warunku ma formę
A. (a>0) && ((b>=10) && (b<=100))
B. (a>0) || ((b>=10) && (b<=100))
C. (a>0) && ((b>=10) || (b<=100))
D. (a>0) || ((b>=10) || (b<=100))
Warunek zapisany w języku JavaScript jako (a>0) || ((b>=10) && (b<=100)) jest poprawny, ponieważ spełnia wymagania dotyczące sprawdzenia, czy zmienna a jest liczbą naturalną dodatnią oraz czy zmienna b mieści się w przedziale od 10 do 100. Wyrażenie logiczne wykorzystuje operator || (alternatywa), który zwraca true, jeśli przynajmniej jeden z warunków jest spełniony. Warunek a>0 zapewnia, że zmienna a jest większa od zera, co jest zgodne z definicją liczb naturalnych dodatnich. Z kolei wyrażenie (b>=10) && (b<=100) sprawdza, czy zmienna b jest w zadanym przedziale, co jest zgodne z wymaganiami. Wartości graniczne 10 i 100 są uwzględnione dzięki operatorowi && (konjunkcja), który wymaga, aby oba warunki były prawdziwe, aby całe wyrażenie zwróciło true. W praktyce, takie podejście można wykorzystać w różnych kontekstach, np. walidacji danych wejściowych w formularzach internetowych, gdzie kluczowe jest zapewnienie, że użytkownik wprowadza poprawne wartości. Tego rodzaju wyrażenia logiczne są fundamentem programowania w JavaScript, umożliwiając tworzenie bardziej złożonych logik aplikacji. Zgodnie z dokumentacją ECMAScript, użycie operatorów logicznych jest standardowym sposobem na przetwarzanie warunków w programowaniu.