Pytanie 1
Tabele Osoby i Adresy są połączone relacją jeden do wielu. Jakie zapytanie SQL należy zapisać, aby korzystając z tej relacji, prawidłowo wyświetlić nazwiska oraz przyporządkowane im miasta?
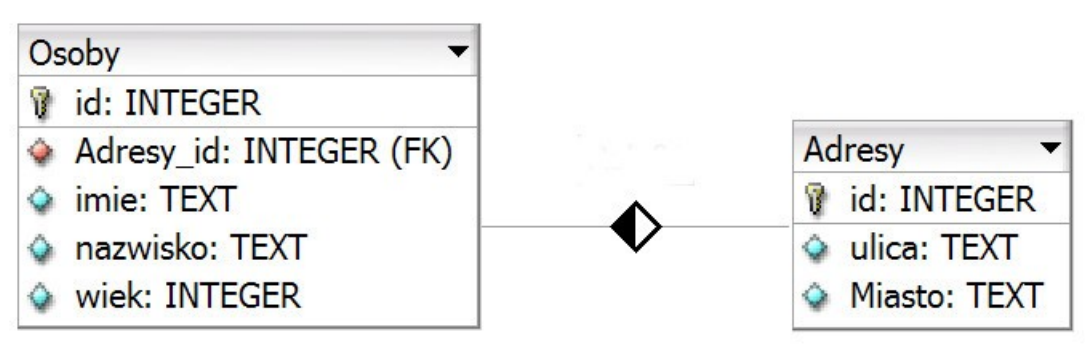
A. SELECT nazwisko, Miasto FROM Osoby JOIN Adresy ON Osoby.Adresy_id = Adresy.id;
B. SELECT nazwisko, Miasto FROM Osoby, Adresy WHERE Osoby.id = Adresy.id;
C. SELECT nazwisko, Miasto FROM Osoby, Adresy;
D. SELECT nazwisko, Miasto FROM Osoby.Adresy_id = Adresy.id FROM Osoby, Adresy;
Błędne odpowiedzi pokazują typowe nieporozumienia związane ze składnią i logiką SQL. Niektóre z nich opierają się na błędnym założeniu, że po prostu wymienienie tabel w instrukcji FROM automatycznie połączy te tabele - to nie jest prawda, ponieważ wymaga to jasno określonego warunku połączenia. Inne błądne odpowiedzi sugerują, że można po prostu porównać wartości kolumny 'id' w obu tabelach, aby je połączyć. To jest błędne, ponieważ nie uwzględnia to faktu, że relacja między tabelami jest określona przez klucz obcy, który może nie mieć takiej samej nazwy ani wartości jak klucz główny. Wreszcie, niektóre błędne odpowiedzi mylą składnię zapytania, umieszczając warunek łączenia w niewłaściwym miejscu lub pomijając niezbędne słowo kluczowe JOIN. To pokazuje, jak ważne jest dokładne zrozumienie składni SQL i jej reguł.