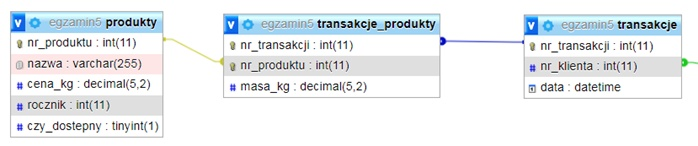
Pytanie 1
Jakie imiona spełniają warunek klauzuli LIKE w zapytaniu
SELECT imie FROM mieszkancy WHERE imie LIKE 'o_%_a';?
A. Oksana, Ola, Olga
B. Oktawia, Oktawian, Olga
C. Oksana, Oktawia, Olga
D. Oda, Oksana, Oktawia
Odpowiedź Oksana, Oktawia, Olga jest poprawna, ponieważ wszystkie te imiona spełniają warunki klauzuli LIKE w zapytaniu SQL. Klauzula LIKE 'o_%_a' wskazuje na to, że imię musi zaczynać się na literę 'o', mieć co najmniej jeden dowolny znak po 'o' (reprezentowany przez znak podkreślenia '_'), a następnie musi kończyć się na literę 'a'. Przykłady imion: Oksana zaczyna się na 'O', ma 'ks' jako drugi znak i kończy się na 'a'; Oktawia również dostosowuje się do tego wzoru, zaś Olga zaczyna się na 'O', ma 'lg' jako drugi i trzeci znak oraz kończy na 'a'. W praktyce, umiejętność korzystania z klauzuli LIKE jest kluczowa w SQL przy wyszukiwaniu danych według wzorców, co pozwala na bardziej elastyczne i precyzyjne zapytania. Poprawne użycie LIKE zwiększa efektywność filtrowania danych, co jest istotnym aspektem w zarządzaniu bazami danych oraz analizie danych, zgodnie z najlepszymi praktykami w branży.