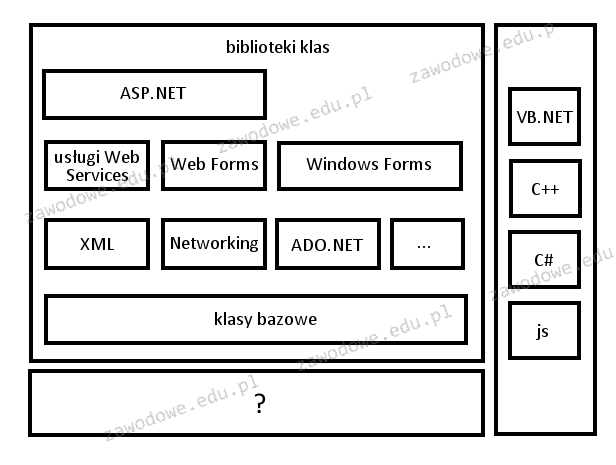
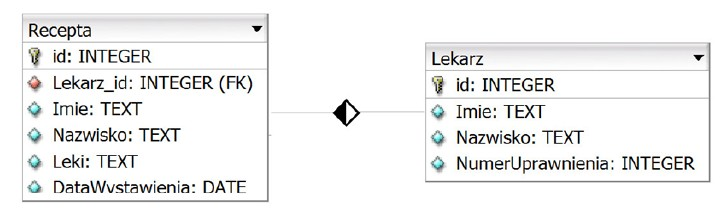
Pytanie 1
Zarządzanie procesem przekształcania kodu źródłowego stworzonego przez programistę na kod maszynowy, który jest zrozumiały dla komputera, nosi nazwę
A. rozpoczynanie
B. kompilowanie
C. wdrażanie
D. analizowanie
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Kompilowanie to proces, w którym kod źródłowy, napisany w języku programowania wysokiego poziomu, jest przekształcany na kod maszynowy, który może być zrozumiany i wykonany przez komputer. Działa to na zasadzie analizy składniowej i semantycznej kodu źródłowego, a następnie generowania odpowiednich instrukcji dla procesora. Przykładem narzędzi, które realizują ten proces, są kompilatory, takie jak GCC dla języka C czy javac dla języka Java. Kompilowanie ma kluczowe znaczenie w programowaniu, ponieważ pozwala na optymalizację kodu, co zwiększa wydajność aplikacji. Dobre praktyki wskazują, że kompilowanie powinno być częścią cyklu programowania, a regularne kompilowanie kodu pomaga w szybszym wykrywaniu błędów oraz zapewnia, że kod jest zawsze zgodny z wymaganiami projektowymi. Warto również zaznaczyć, że proces kompilacji może obejmować różne etapy, takie jak prekompilacja, generacja kodu pośredniego oraz linkowanie, co czyni go złożonym i wieloetapowym działaniem.
Kompilowanie to proces, w którym kod źródłowy, napisany w języku programowania wysokiego poziomu, jest przekształcany na kod maszynowy, który może być zrozumiany i wykonany przez komputer. Działa to na zasadzie analizy składniowej i semantycznej kodu źródłowego, a następnie generowania odpowiednich instrukcji dla procesora. Przykładem narzędzi, które realizują ten proces, są kompilatory, takie jak GCC dla języka C czy javac dla języka Java. Kompilowanie ma kluczowe znaczenie w programowaniu, ponieważ pozwala na optymalizację kodu, co zwiększa wydajność aplikacji. Dobre praktyki wskazują, że kompilowanie powinno być częścią cyklu programowania, a regularne kompilowanie kodu pomaga w szybszym wykrywaniu błędów oraz zapewnia, że kod jest zawsze zgodny z wymaganiami projektowymi. Warto również zaznaczyć, że proces kompilacji może obejmować różne etapy, takie jak prekompilacja, generacja kodu pośredniego oraz linkowanie, co czyni go złożonym i wieloetapowym działaniem.