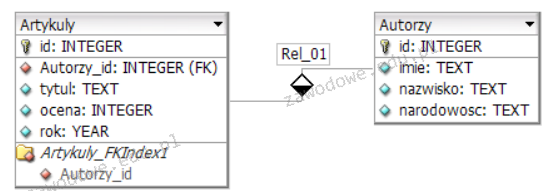
Pytanie 1
Jakie znaczniki należy zastosować, aby umieścić kod PHP w pliku z rozszerzeniem php?
A. <php .......... />
B. <?php> ........ <php?>
C. <php> ......... </php>
D. <?php .......... ?>
Odpowiedź <?php .......... ?> jest poprawna, ponieważ jest to standardowy sposób wstawiania kodu PHP do plików z rozszerzeniem .php. Znaczniki te pozwalają interpreterowi PHP rozpoznać, że zawarty w nich kod powinien być przetworzony przez silnik PHP, a nie przez przeglądarkę jako HTML. W praktyce, użycie tych znaczników umożliwia twórcom aplikacji webowych dynamiczne generowanie treści, operowanie na danych wejściowych oraz integrację z bazami danych. Przykład zastosowania może obejmować skrypty do przetwarzania formularzy, generowania stron internetowych w zależności od warunków lub wyświetlania danych z bazy danych. Standardowe znaczniki <?php ?> są również zalecane w dokumentacji PHP jako najlepsza praktyka, co zapewnia większą kompatybilność i zrozumiałość kodu, a także minimalizuje ryzyko błędów związanych z interpretacją kodu przez serwer. Warto również pamiętać, że znaczniki te powinny być stosowane z zachowaniem odpowiednich zasad formatowania, aby kod był czytelny i łatwy do utrzymania.