Pytanie 1
Jakie są właściwe etapy tworzenia bazy danych?
A. Zdefiniowanie celu, normalizacja, stworzenie tabel, utworzenie relacji
B. Zdefiniowanie celu, utworzenie relacji, stworzenie tabel, normalizacja
C. Zdefiniowanie celu, normalizacja, utworzenie relacji, stworzenie tabel
D. Zdefiniowanie celu, stworzenie tabel, utworzenie relacji, normalizacja
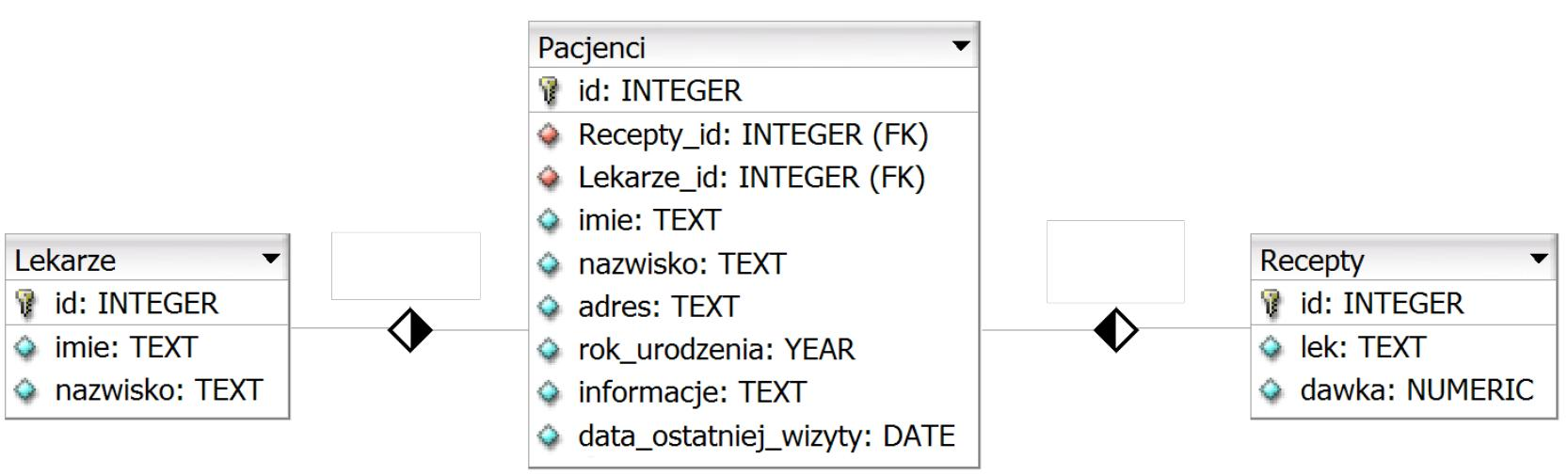
W procesie tworzenia bazy danych kluczowym pierwszym krokiem jest określenie celu, który pozwala zrozumieć, jakie dane będą gromadzone oraz jakie operacje będą na nich wykonywane. Następnie przystępuje się do stworzenia tabel, które stanowią fundamentalne elementy bazy danych. Każda tabela powinna odpowiadać określonym kategoriom danych, a ich struktura powinna być dobrze przemyślana, aby umożliwić efektywne przechowywanie, zarządzanie oraz odczytywanie informacji. Po utworzeniu tabel ważne jest, aby zdefiniować relacje między nimi, co umożliwia integrację danych oraz ich logiczne powiązanie. Na końcu procesu następuje normalizacja, która ma na celu eliminację redundancji danych oraz zwiększenie integralności bazy, co przekłada się na jej wydajność. Przykładem może być stworzenie bazy danych dla systemu zarządzania uczelnią, gdzie tabele odpowiadają za studentów, kursy i wykładowców. Właściwe zdefiniowanie relacji pomoże w zrozumieniu, którzy studenci uczą się na jakich kursach, a normalizacja zabezpieczy przed powielaniem danych.