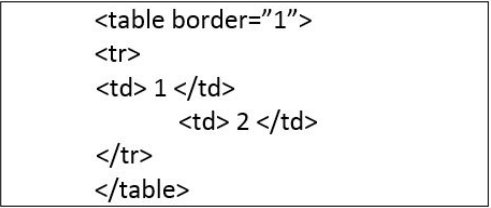
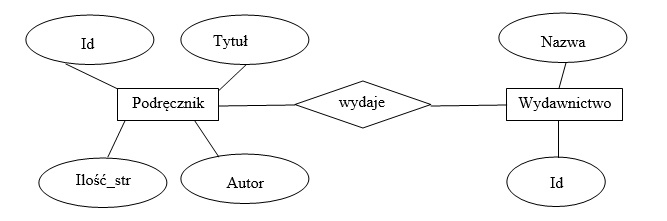
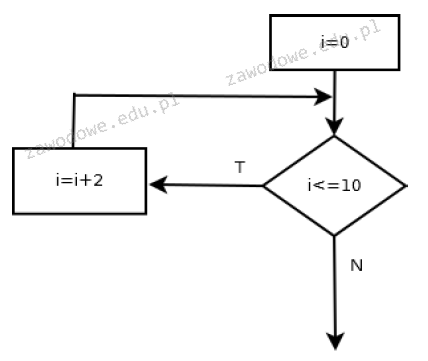
Pytanie 1
Rodzaj zmiennej w języku JavaScript
A. musi być zadeklarowany na początku skryptu.
B. ma miejsce poprzez przypisanie wartości.
C. nie istnieje.
D. jest tylko jeden rodzaj.
W języku JavaScript typ zmiennej jest dynamicznie określany na podstawie wartości przypisanej do tej zmiennej. Oznacza to, że nie ma potrzeby deklarowania typu zmiennej przed jej użyciem. Na przykład, możemy stworzyć zmienną 'x' i przypisać jej wartość liczbową: 'let x = 10;'. W późniejszym czasie możemy przypisać do niej wartość tekstową: 'x = 'Hello!';' bez jakichkolwiek błędów. To zjawisko wpisuje się w koncepcję typowania dynamicznego, która jest cechą języków takich jak JavaScript. Dzięki temu programiści mogą pisać bardziej elastyczny kod, co jest szczególnie przydatne w projektach, gdzie wymagania mogą się szybko zmieniać. Praktyczne zastosowanie tego podejścia w JavaScript pozwala na tworzenie funkcji, które mogą przyjmować różne typy danych, co zwiększa ich uniwersalność i użyteczność. Warto również zauważyć, że dobrym zwyczajem jest stosowanie odpowiednich konwencji nazw zmiennych oraz ich dokumentowanie, aby zwiększyć czytelność kodu w projektach zespołowych.