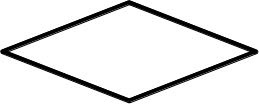
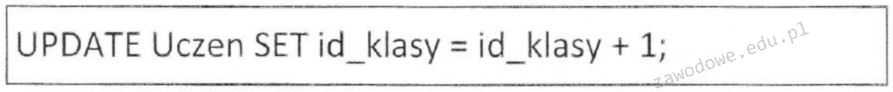Pytanie 1
W którym z bloków powinien znaleźć się warunek pętli?

A. C.
B. A.
C. D.
D. B.
Blok oznaczony literą C jest symbolem decyzji w diagramach przepływu i jest używany do umieszczania warunków pętli w programowaniu. Symbol ten, przypominający romb, pozwala na zadanie pytania lub warunku, który decyduje o dalszym przebiegu działania programu. W praktyce, w językach programowania takich jak C++ czy Python, pętle warunkowe takie jak 'while' lub 'for' wymagają zdefiniowania warunku, który kontroluje liczbę iteracji. Blok decyzyjny umożliwia tworzenie logiki kontrolowanej przez dane wejściowe, co jest fundamentalne dla dynamicznych i responsywnych aplikacji. Zastosowanie bloku decyzyjnego zgodnie ze standardami branżowymi, jak np. UML (Unified Modeling Language), jest kluczowe dla tworzenia zrozumiałych i skalowalnych diagramów przepływu. Dzięki temu, programiści mogą łatwo komunikować algorytmy złożone z sekwencji warunków i decyzji, co jest niezbędne w projektowaniu oprogramowania o dużej złożoności. Praktyczne zrozumienie i stosowanie warunków w blokach decyzyjnych jest kluczowe dla tworzenia efektywnych rozwiązań programistycznych.