Pytanie 1
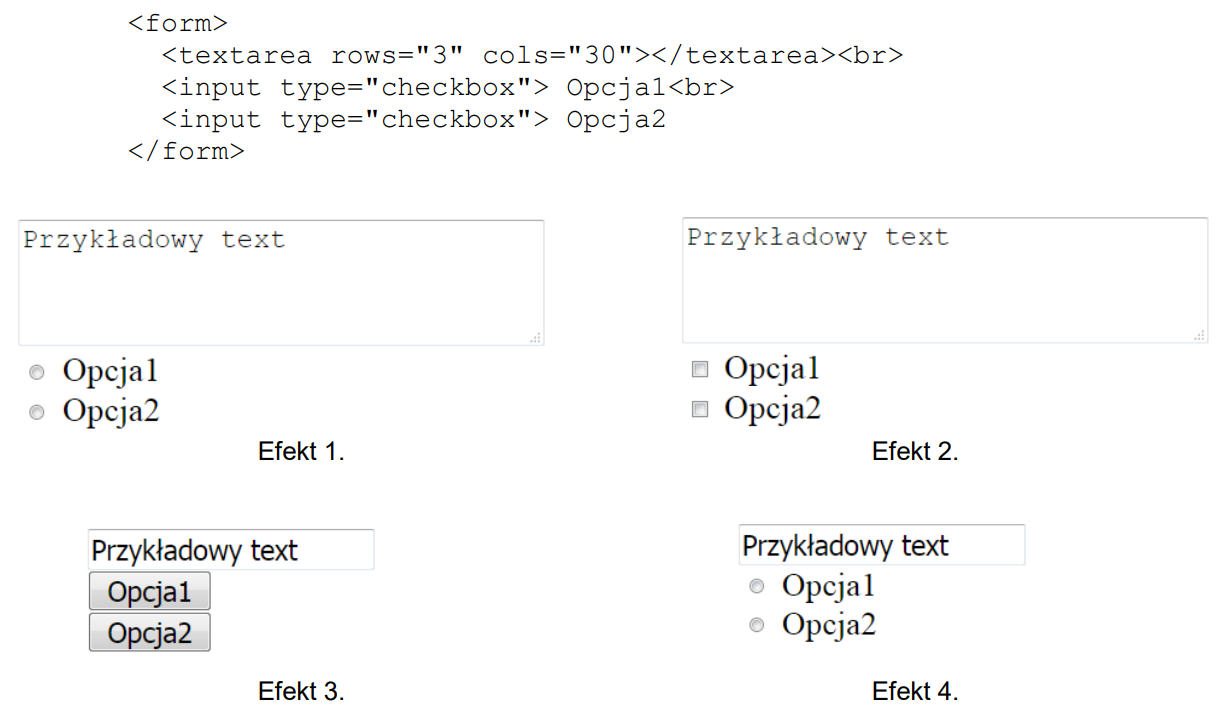
Aby zdefiniować styl akapitu <p>, który występuje bezpośrednio po znaczniku <img>, należy w arkuszu stylów CSS zastosować związek
A. img p
B. img [p]
C. img + p
D. img > p
W tym zadaniu chodzi o zrozumienie tzw. kombinatorów w CSS, czyli znaków łączących selektory i określających relacje między elementami w drzewie DOM. Bardzo często mylenie tych relacji prowadzi do dokładnie takich błędnych odpowiedzi jak w tym pytaniu. Zapis „img p” to selektor potomka (descendant selector). Oznacza on: wybierz każdy element <p>, który znajduje się gdziekolwiek wewnątrz elementu <img>. Problem w tym, że w poprawnym HTML znacznik <img> jest pustym elementem, nie może mieć dzieci. W praktyce więc taki selektor nigdy nie zadziała w opisanym scenariuszu. To typowe nieporozumienie: ktoś myśli „obok obrazka jest paragraf, więc napiszę img p”, ale CSS rozumie to jako relację rodzic–potomek, a nie rodzeństwo. Z kolei zapis „img [p]” wynika zwykle z pomieszania składni selektorów atrybutów z selektorami elementów. Nawiasy kwadratowe w CSS służą do wybierania elementów na podstawie atrybutów, np. a[href], input[type="text"]. Konstrukcja [p] sugerowałaby atrybut o nazwie „p”, co w ogóle nie ma sensu w tym kontekście. Taka składnia jest po prostu niepoprawna merytorycznie, bo nie opisuje żadnej realnej relacji między <img> a <p>. Natomiast „img > p” to selektor dziecka (child combinator). Mówi on: wybierz elementy <p>, które są bezpośrednimi dziećmi elementu <img>. To znowu kłóci się z modelem HTML – obrazek nie może zawierać w sobie paragrafu. Ten selektor ma sens np. przy div > p, ale zupełnie nie pasuje do relacji „element po elemencie”. W tym zadaniu potrzebna jest relacja rodzeństwa: akapit stoi obok obrazka, a nie w środku. Prawidłowe podejście opiera się na zrozumieniu, że chcemy „bezpośredniego sąsiada” na tym samym poziomie, a nie potomka czy dziecka. Właśnie to zapewnia selektor sąsiedniego rodzeństwa, czyli konstrukcja z plusem. Typowy błąd myślowy polega na tym, że patrzymy na wygląd strony (obrazek nad akapitem) i nie analizujemy prawdziwej struktury DOM. Dobra praktyka frontendowa to zawsze przełożyć układ na dokładne relacje: rodzic–dziecko, przodek–potomek, rodzeństwo. Dopiero potem dobrać odpowiedni kombinator w CSS. Jeśli chcemy stylować element „bezpośrednio po”, używamy właśnie selektora z +, a nie spacji czy znaku >.