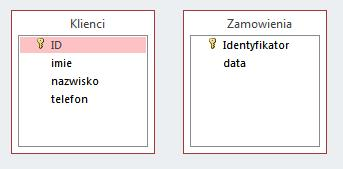
Pytanie 1
Który zbiór znaczników, określających projekt strony internetowej w sposób semantyczny, jest zgodny z normą HTML 5?
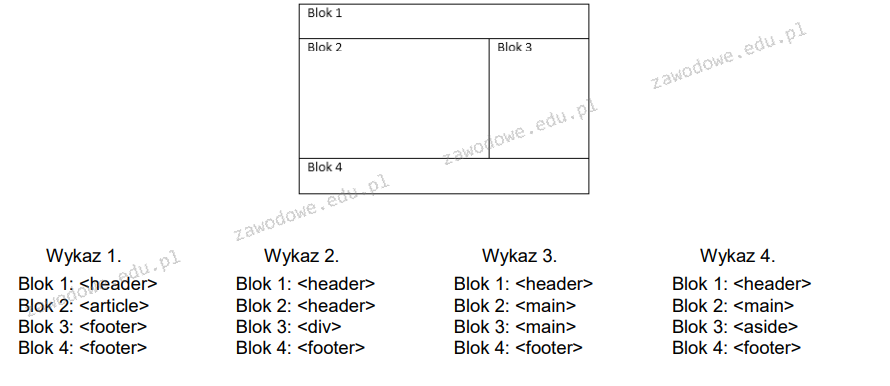
A. Zbiór 3
B. Zbiór 4
C. Zbiór 2
D. Zbiór 1
Wykaz 4 jest zgodny ze standardem HTML 5, ponieważ poprawnie używa semantycznych znaczników do strukturyzacji zawartości strony. <header> jest używany do definiowania nagłówka dokumentu lub sekcji, co jest poprawne dla Bloku 1. Znacznik <main> w Bloku 2 wskazuje na główną treść strony, co jest zgodne z jego przeznaczeniem. <aside> w Bloku 3 jest trafnie używany do treści pobocznych, które są związane, ale niekonieczne dla głównego wątku treści, co odpowiada typowej strukturze witryny, gdzie treści poboczne są często wyświetlane obok głównej treści. Na koniec, <footer> w Bloku 4 jest poprawnie przypisany, gdyż zamyka i podsumowuje zawartość strony. HTML5 kładzie duży nacisk na semantykę, co pomaga w optymalizacji pod kątem SEO oraz ułatwia rozumienie struktury strony zarówno przez ludzi, jak i maszyny. Takie podejście poprawia dostępność, ułatwia stylizowanie za pomocą CSS oraz wspiera lepsze praktyki w zakresie zgodności z przyszłymi standardami.