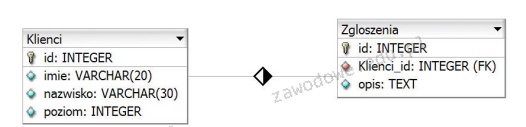
Pytanie 1
W zaprezentowanym fragmencie algorytmu użyto
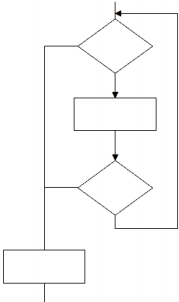
A. dwie pętle.
B. trzy bloki operacyjne (procesy).
C. jedną pętlę.
D. jeden blok decyzyjny.
W przedstawionym fragmencie algorytmu zastosowano jedną pętlę co jest zgodne z poprawną odpowiedzią. Pętla to konstrukcja programistyczna pozwalająca wielokrotnie wykonywać fragment kodu dopóki spełniony jest określony warunek. W analizowanym schemacie widzimy jednokrotną pętlę oznaczoną powrotem do wcześniejszego punktu co jest charakterystyczne dla takich struktur. Najczęściej używane pętle to for while i do-while różniące się sposobem sprawdzania warunku początkowego. Pętle są fundamentalne w algorytmice i pozwalają na realizację złożonych operacji takich jak iteracja po tablicach czy przetwarzanie danych wejściowych. Ich zastosowanie zwiększa efektywność kodu i upraszcza jego strukturę. Dobrą praktyką jest dbanie o czytelność pętli i unikanie skomplikowanych zależności co poprawia zrozumienie kodu przez innych programistów. Warto również pamiętać o zasadach optymalizacji np. minimalizowanie liczby iteracji co przekłada się na lepszą wydajność.