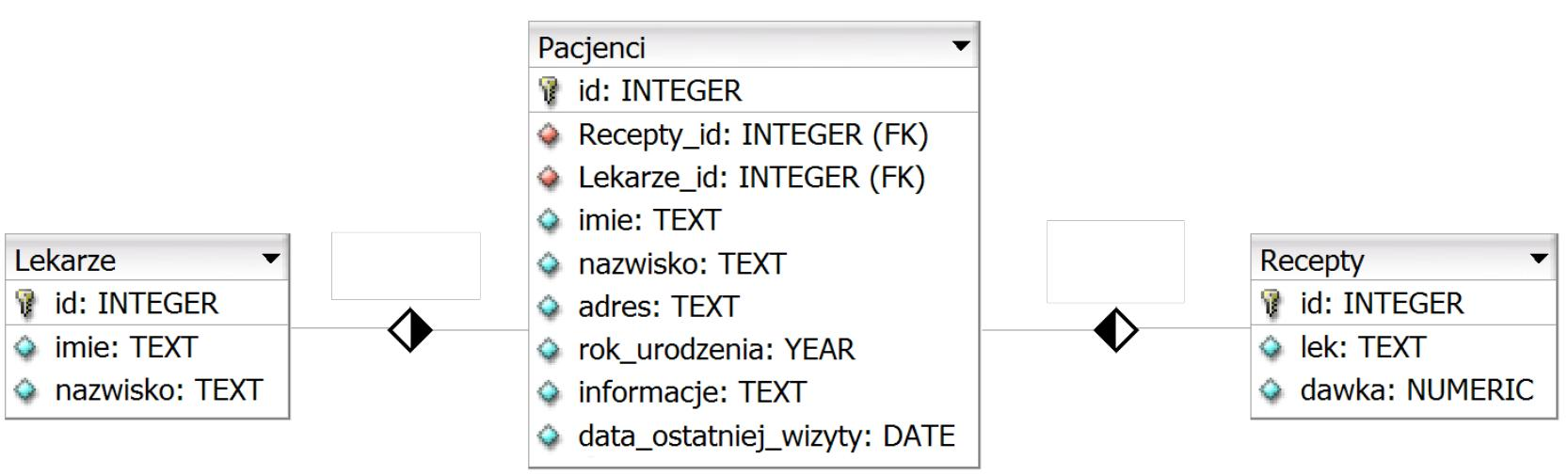
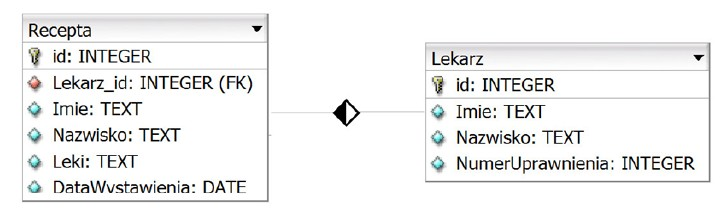
Pytanie 1
Po uruchomieniu zamieszczonego w ramce skryptu w języku JavaScript, w przeglądarce zostanie wyświetlona wartość:
var a = 5; var b = a--; a *= 3; document.write(a + "," + b);
A. 15,5
B. 15,4
C. 12,4
D. 12,5
W tym skrypcie JavaScript mamy operator dekrementacji a--, gdzie najpierw wartość zmiennej a jest przypisana do zmiennej b, a dekrementacja następuje później. Jeśli tego nie rozumiesz, może to prowadzić do różnych nieporozumień co do wynikowych wartości. Czyli po a-- b przyjmuje pierwotną wartość a, która wynosi 5. Warto zrozumieć kolejność operacji, bo przy operatorze postfix zmiana wartości następuje po przypisaniu. Później, po dekrementacji, a staje się 4, co czasem jest źle interpretowane, bo ludzie myślą, że b też by się zmieniło. Potem jest a *= 3, gdzie 4 mnożymy przez 3 i dostajemy 12. Często ludzie popełniają błąd, zakładając, że operatory działają równocześnie w jednym wierszu kodu. Ważne jest, żeby znać te subtelności, bo pomaga to w lepszym programowaniu i kontrolowaniu, jak zmienne się zmieniają.