Pytanie 1
Narzędzie zaprezentowane na ilustracji służy do
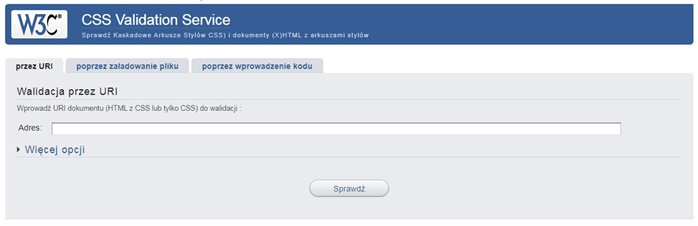
A. debugowania strony internetowej
B. walidacji stylów CSS
C. sprawdzania zgodności witryny ze standardem HTML5
D. walidacji kodu HTML i XHTML
Narzędzie przedstawione na ilustracji to usługa walidacji CSS stworzona przez World Wide Web Consortium (W3C). Jego głównym celem jest sprawdzanie poprawności arkuszy stylów CSS pod kątem zgodności z obowiązującymi standardami. Walidacja CSS pozwala na identyfikację błędów składniowych oraz niepoprawnych wartości, co jest kluczowe dla zapewnienia spójności wyglądu strony w różnych przeglądarkach. Korzystanie z walidatora CSS jest częścią dobrych praktyk w procesie tworzenia stron internetowych, ponieważ poprawny kod CSS zwiększa dostępność i użyteczność serwisów. Praktycznym przykładem użycia tego narzędzia jest proces optymalizacji strony internetowej, gdzie walidator pomaga w eliminacji błędów, które mogą prowadzić do nieprzewidywalnego zachowania witryny. Dzięki walidacji możemy również upewnić się, że nasze arkusze stylów są zgodne z najnowszymi standardami, co jest istotne dla przyszłej kompatybilności serwisu.
