Pytanie 1
Wskaż termin, który w języku angielskim odnosi się do "testów wydajnościowych"?
A. security testing
B. integration testing
C. unit testing
D. performance testing
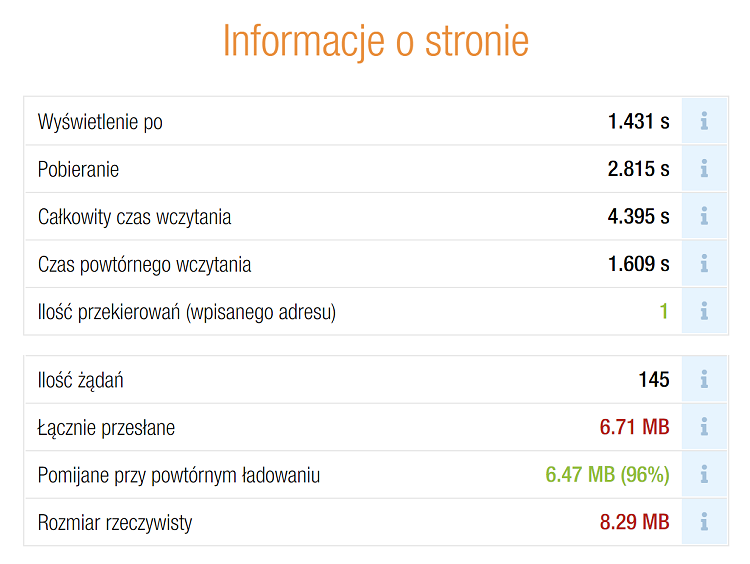
Testy wydajnościowe, czyli performance testing, to coś, co naprawdę warto mieć na uwadze. Dzięki nim możemy sprawdzić, jak nasza aplikacja działa pod dużym obciążeniem i jak szybko odpowiada na różne żądania. Moim zdaniem, to kluczowy aspekt, zwłaszcza jeśli planujemy, żeby nasza aplikacja miała wielu użytkowników. W końcu, nikt nie lubi czekać, aż coś się załaduje!