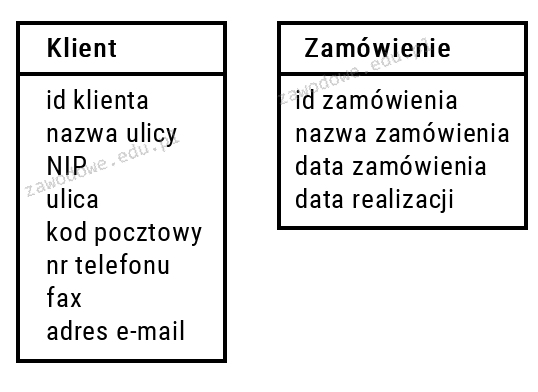
Pytanie 1
Funkcja napisana w PHP ma na celu
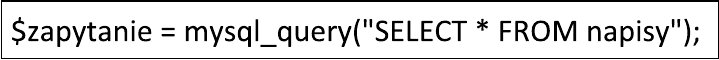
A. pobranie informacji z bazy danych
B. ustawienie hasła do bazy danych
C. nawiązanie połączenia z bazą danych
D. zabezpieczenie bazy danych
Ustawienie hasła do bazy danych nie jest realizowane przez zapytanie SQL w PHP lecz przez konfigurację połączenia z bazą danych zwykle przy użyciu funkcji mysql_connect lub mysqli_connect gdzie hasło jest jednym z parametrów. Zabezpieczenie bazy danych nie polega na prostym zapytaniu lecz wymaga szerszego podejścia obejmującego kontrolę dostępu zarządzanie uprawnieniami szyfrowanie danych i ochronę przed atakami SQL Injection. Połączenie z bazą danych w PHP realizowane jest poprzez funkcje umożliwiające nawiązanie sesji z serwerem bazodanowym jak mysql_connect lub nowocześniejsze mysqli_connect oraz obiekty PDO które oferują bardziej zaawansowane mechanizmy zarządzania połączeniami. Często występującym błędem jest mylenie funkcji odpowiedzialnych za zarządzanie połączeniem z funkcjami wykonującymi operacje na danych. Mylenie tych dwóch aspektów pracy z bazą danych prowadzi do błędów w aplikacjach jak niewłaściwe zarządzanie zasobami lub podatność na ataki. Nowoczesne podejścia takie jak stosowanie ORM-ów jak Doctrine w PHP abstrahują wiele tych mechanizmów co upraszcza zarządzanie tymi aspektami w kodzie. Ważnym aspektem jest także stosowanie praktyk bezpieczeństwa takich jak walidacja i sanitizacja danych oraz używanie przygotowanych wyrażeń co jest kluczowe w ochronie danych i zapewnieniu prawidłowego działania aplikacji. Zrozumienie tych podstawowych elementów jest kluczowe w tworzeniu bezpiecznych i wydajnych aplikacji bazodanowych.