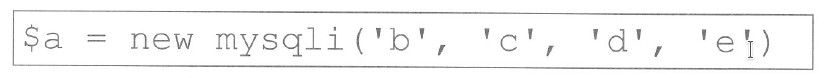Pytanie 1
W języku PHPnie ma możliwości
A. przetwarzanie danych z formularzy
B. obróbka informacji przechowywanych w bazie danych
C. tworzenie dynamicznej zawartości strony internetowej
D. zmienianie dynamiczne treści strony HTML w przeglądarce
Pomimo powszechnej wiedzy o zastosowaniach PHP, istnieje pewne nieporozumienie dotyczące jego funkcji w kontekście dynamicznych zmian na stronach internetowych. PHP jest używane do przetwarzania danych po stronie serwera, co oznacza, że jego zadaniem jest generowanie treści, które są następnie wysyłane do przeglądarki użytkownika. Pierwsza z niepoprawnych odpowiedzi sugeruje, że PHP może przetwarzać dane zgromadzone w bazie danych, co jest prawdą, jednak nie odnosi się do sedna pytania. PHP efektywnie współpracuje z bazami danych za pomocą zapytań SQL, ale to, co jest zwracane, to statyczny kod HTML. W kontekście generowania dynamicznej zawartości strony, PHP może być użyte do stworzenia HTML, ale nie do jego późniejszej modyfikacji w przeglądarce. Odpowiedź dotycząca generowania dynamicznej zawartości nie uwzględnia, że zmiany te są wynikiem działania PHP przed wysłaniem danych do klienta. Kolejna odpowiedź, sugerująca, że PHP może bezpośrednio zmieniać HTML w przeglądarkach, myli funkcjonalności języka. Nowoczesne aplikacje webowe często wykorzystują JavaScript do interakcji z użytkownikiem po załadowaniu strony, co pozwala na dynamiczne zmiany bez konieczności ponownego ładowania strony. Również przetwarzanie danych formularzy jest zadaniem, które PHP wykonuje, ale dotyczy to głównie zbierania i przesyłania danych do serwera, a nie modyfikacji treści na stronie po jej załadowaniu. Podsumowując, kluczowym aspektem jest zrozumienie, że PHP jest językiem po stronie serwera, a wszelkie dynamiczne interakcje w przeglądarkach powinny być zarządzane za pomocą technologii klienckich, takich jak JavaScript, co jest zgodne z aktualnymi standardami tworzenia aplikacji webowych.