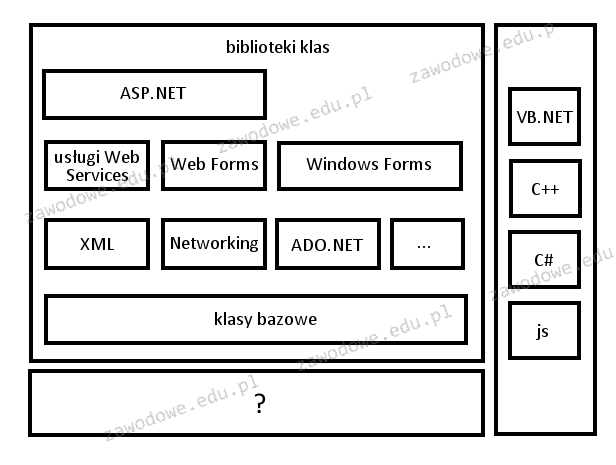
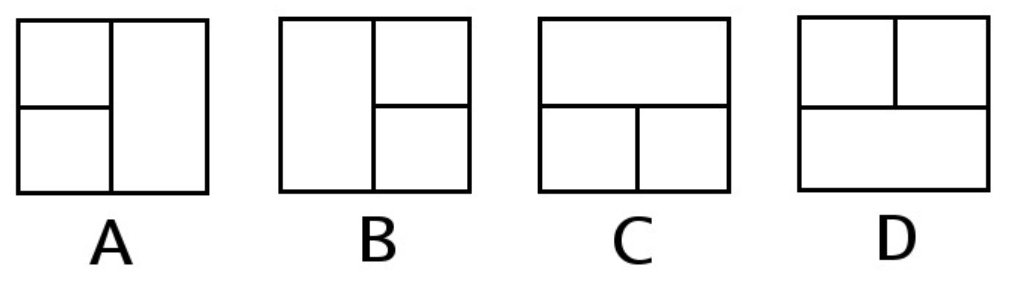
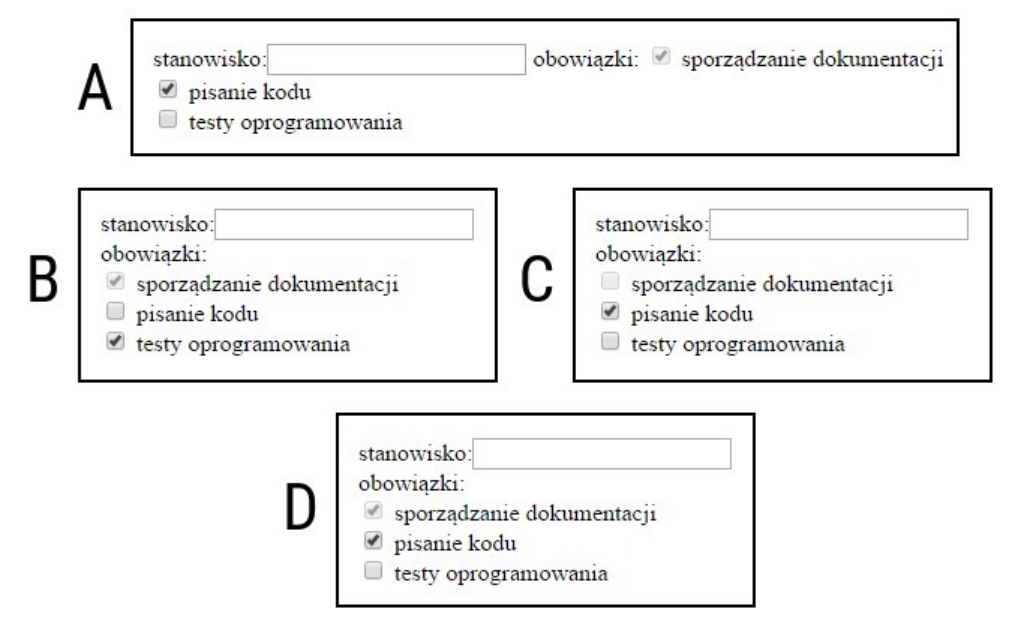
Pytanie 1
Zestawienie dwóch kolorów znajdujących się naprzeciwko siebie w kole kolorów jest zestawieniem
A. dopełniającym
B. monochromatycznym
C. sąsiadującym
D. trójkątnym
Wybór odpowiedzi trójkątnym odnosi się do koncepcji, w której kolory są rozmieszczone w formie trójkąta na kole barw. Takie połączenie nie tworzy jednak charakterystycznej relacji, jaką posiadają kolory dopełniające. W praktyce, kolory trójkątne służą do tworzenia bardziej złożonych palet, gdzie każdy kolor współdziała z pozostałymi, ale nie generują one tak silnego kontrastu jak dopełniające. Odpowiedź sąsiadującym sugeruje, że barwy są blisko siebie w kole barw, co prowadzi do harmonijnego, ale jednolitego efektu, a nie do wyraźnych kontrastów. Barwy sąsiadujące można stosować do uzyskania delikatniejszych przejść kolorystycznych, co jest przydatne w projektach, które wymagają subtelności. Z kolei monochromatycznym odnosi się do jednego koloru i jego odcieni, co pozwala na stworzenie spójnej, ale mało zróżnicowanej palety kolorystycznej. Użycie monochromatycznych kolorów może być przydatne do zbudowania jednolitego stylu, lecz nie oferuje ono intensywności wizualnej, którą uzyskuje się dzięki kolorom dopełniającym. Generalnie, błędne podejścia do kolorów mogą prowadzić do ograniczenia kreatywności i nieefektywnego wykorzystania kolorystyki w projektach artystycznych czy graficznych. Zrozumienie różnic między tymi połączeniami jest kluczowe dla efektywnego wykorzystania teorii kolorów w praktycznych zastosowaniach.