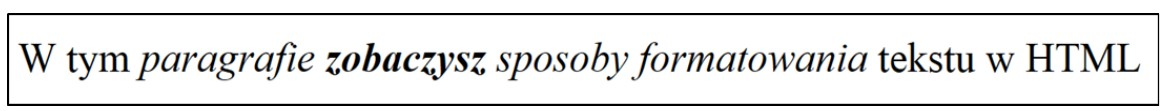Pytanie 1
Kod JavaScript ma za zadanie szukanie wartości maksymalnej w tablicy. Wskaż błąd występujący w skrypcie.
14 max = tablica[0];
15 for (j == 1; j < 9; j++) {
16 if (max <= tablica[j]) {
17 max = tablica[j];
18 };
19 };
20 document.write("Największy element tablicy to: " + max);A. Warunek w linii 16 powinien być odwrócony.
B. Zmienna max ma niewłaściwie przypisaną wartość w linii 14.
C. Kod zapisany w linii 20 ma nieprawidłową składnię.
D. Zastosowano operator porównania zamiast przypisania w linii 15.
Kod, który ma znaleźć wartość maksymalną w tablicy, jest w gruncie rzeczy poprawny algorytmicznie, a główny problem leży w składni pętli. Łatwo jednak skupić się na innych fragmentach i szukać błędu tam, gdzie go nie ma. Spójrzmy po kolei na wszystkie podejrzane miejsca. Warunek w instrukcji `if (max <= tablica[j])` może wyglądać podejrzanie, bo często w przykładach używa się operatora `<`. Jednak użycie `<=` nie jest błędem. To znaczy tylko tyle, że jeśli w tablicy występuje kilka identycznych wartości maksymalnych, to `max` przyjmie wartość ostatniego z nich. Algorytm nadal zwróci poprawne maksimum, różnica dotyczy jedynie tego, który indeks „wygra”, jeśli wartości są równe. Z punktu widzenia wyszukiwania największej liczby to zachowanie jest całkowicie akceptowalne. Pojawia się też pokusa, żeby winić linię z `document.write(...)`. Ten zapis jest składniowo poprawny w JavaScripcie: mamy wywołanie metody `write` na obiekcie `document` i konkatenację napisu z wartością zmiennej. Można dyskutować, czy jest to dobra praktyka w nowoczesnych aplikacjach (zwykle lepiej manipulować DOM, np. przez `textContent`), ale nie jest to błąd uniemożliwiający działanie programu. Podobnie przypisanie `max = tablica[0];` jest typowym i poprawnym sposobem inicjalizacji zmiennej maksimum: zakładamy na start, że największym elementem jest pierwszy element tablicy i dopiero później weryfikujemy to w pętli. Tu nie ma żadnej sprzeczności z logiką algorytmu. Prawdziwy problem to użycie operatora porównania `==` w miejscu, gdzie powinniśmy zainicjalizować licznik pętli. Konstrukcja `for (j == 1; j < 9; j++)` nie ustawia wartości `j`, tylko sprawdza, czy aktualne `j` jest równe 1, przez co cała pętla ma niepoprawną składnię. Typowy błąd myślowy polega tutaj na utożsamieniu „ustawienia na 1” z „sprawdzeniem, czy jest równe 1”. W językach imperatywnych to są zupełnie różne operacje. Dobra praktyka to zawsze czytać nagłówek pętli jak zdanie: „ustaw j na 1; dopóki j < 9; po każdej iteracji zwiększ j o 1”. Jeśli to czytanie nie ma sensu, znaczy że coś jest nie tak z operatorem. Warto też pamiętać, że narzędzia linterskie i tryb `use strict` pomagają wychwycić takie pomyłki, zanim trafią one do gotowego kodu.