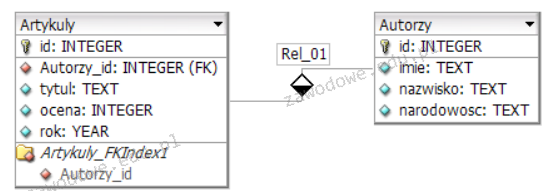
Pytanie 1
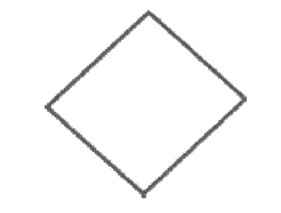
Która komenda algorytmu odpowiada graficznej wizualizacji bloku przedstawionego na ilustracji?
A. Wykonaj podprogram sortowania tablicy t
B. n <- n + 5
C. Wypisz n
D. n > 20
Analizując dostępne opcje należy zrozumieć że poprawna identyfikacja elementów algorytmu zależy od znajomości symboli używanych w schematach blokowych. Wybór n>20 jako poprawnej odpowiedzi wynika z rozpoznania rombu jako symbolu decyzji. Opcja Wypisz n sugeruje operację wyjściową która w schematach blokowych zwykle reprezentowana jest przez prostokąt z zakrzywionymi narożnikami co oznacza wyświetlanie wartości zmiennej. Instrukcja n <- n + 5 jest przykładem operacji przypisania lub inkrementacji która zazwyczaj oznacza modyfikację wartości zmiennej i byłaby przedstawiona jako prostokąt oznaczający proces. Natomiast Wykonaj podprogram sortowania tablicy t to wywołanie funkcji które także mieści się w zakresie standardowego bloku procesowego. Wybór tych opcji wskazuje na brak poprawnego zrozumienia jakie typy operacji reprezentują różne kształty w schematach blokowych co może prowadzić do błędów w projektowaniu algorytmów. Zrozumienie znaczenia każdego bloku jest kluczowe w procesie tworzenia dokładnych i funkcjonalnych modeli algorytmicznych które są podstawą efektywnego rozwiązywania problemów w informatyce i inżynierii oprogramowania. Warto zwrócić uwagę na standardy takie jak UML czy BPMN które także definiują podobne symbole i konwencje co ułatwia komunikację i dokumentację w zespołach projektowych.