Pytanie 1
W danym środowisku programistycznym, aby uzyskać dostęp do listy błędów składniowych po nieudanej kompilacji, należy użyć kombinacji klawiszy
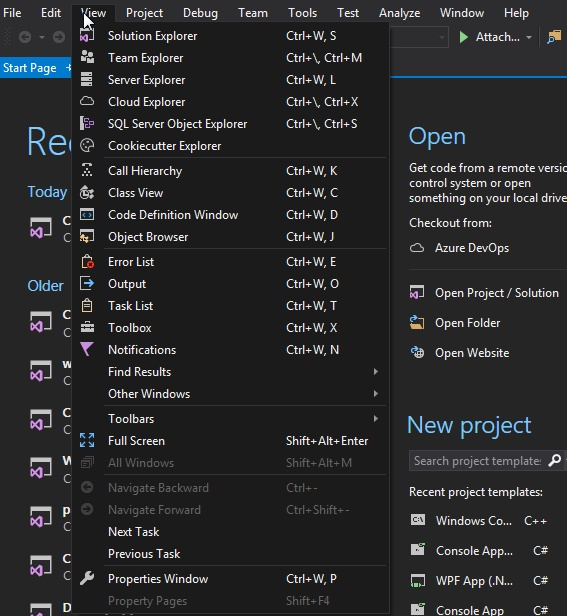
A. Ctrl+W, T
B. Ctrl+W, N
C. Ctrl+W, E
D. Ctrl+W, O
W środowisku Visual Studio zrozumienie, które skróty klawiaturowe przypisane są do specyficznych funkcji, jest kluczowe dla efektywnej pracy programisty. Odpowiedzi błędne sugerują inne kombinacje klawiszy, które nie są przypisane do wyświetlania listy błędów. Na przykład Ctrl+W, O często jest skojarzone z otwieraniem konkretnej funkcjonalności czy widoku w innych programach, ale w Visual Studio nie odpowiada za listę błędów. Podobnie Ctrl+W, T i Ctrl+W, N również odnoszą się do innych zadań, takich jak otwieranie okna Zarządzania Zadaniami czy Notyfikacji. Błędne przyporządkowanie tych funkcji może wynikać z braku znajomości specyficznych dla Visual Studio skrótów lub z mylnego przenoszenia wiedzy z innego oprogramowania, które może używać podobnych kombinacji do innych celów. Typowym błędem myślowym jest zakładanie, że wszystkie zintegrowane środowiska programistyczne działają w podobny sposób lub że skróty klawiszowe są unifikowane pomiędzy różnymi platformami i aplikacjami. Dlatego tak ważne jest, by każdy korzystający z Visual Studio zapoznał się z dokumentacją i dostępnymi skrótami klawiaturowymi, aby móc efektywnie nawigować i korzystać z funkcji oferowanych przez to zaawansowane narzędzie.