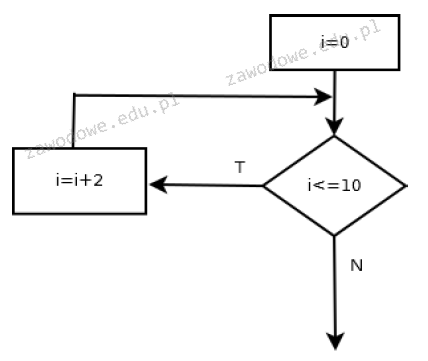
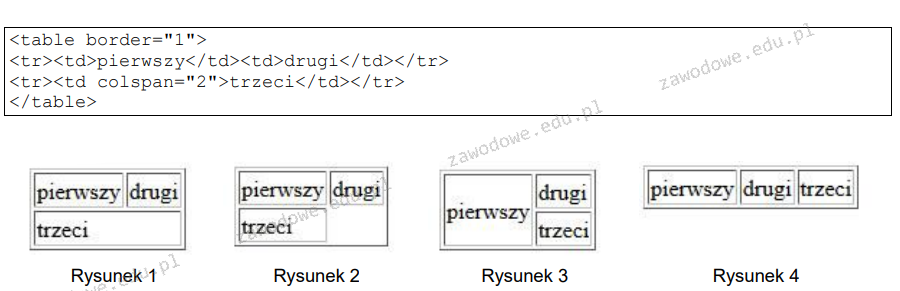
Pytanie 1
Fragment kodu SQL wskazuje, że klucz obcy

A. jest ustawiony na kolumnie obiekty
B. jest obecny w tabeli obiekty
C. wiąże się z kolumną imiona
D. stanowi odniesienie do siebie samego
Klucz obcy w SQL nie umieszcza się w kolumnie obiekty, ani nie jest referencją do samego siebie. Główną funkcją klucza obcego jest zapewnienie, że dane w jednej tabeli są zgodne z danymi w innej tabeli, co jest podstawą utrzymania integralności referencyjnej w bazie danych. Po pierwsze, klucz obcy nie odnosi się do samego siebie, ponieważ jego celem jest wskazywanie na klucze główne lub unikalne kolumny w innej tabeli. Samoistne odniesienie nie miałoby sensu w kontekście zapewniania spójności danych. Po drugie, klucz obcy nie jest fizycznie umieszczony w jakiejkolwiek kolumnie w tabeli obiekty. Zamiast tego, jego definicja w kodzie SQL wskazuje, że istnieje logiczne powiązanie między kolumnami dwóch tabel. Istnieje również mylne założenie, że klucz obcy może być ustawiony na dowolną kolumnę w tabeli, na przykład w tabeli obiekty. W rzeczywistości klucz obcy musi być zdefiniowany w kontekście relacji między dwiema tabelami, a jego zadaniem jest wskazywanie na kolumnę w tabeli docelowej, która powinna zawierać wartości odpowiadające wartościom w kolumnie źródłowej. Takie niejasne rozumienie klucza obcego może prowadzić do błędów w projektowaniu struktury baz danych, co w dłuższej perspektywie może skutkować problemami z integralnością danych i wydajnością zapytań do bazy danych. Zrozumienie poprawnego zastosowania kluczy obcych jest kluczowe dla skutecznego zarządzania relacyjnymi bazami danych, dlatego ważne jest unikanie tych typowych błędów przy ich implementacji.