Pytanie 1
Wykonano następującą kwerendę na tabeli Pracownicy:
SELECT imie FROM pracownicy WHERE nazwisko = 'Kowal' OR stanowisko > 2;
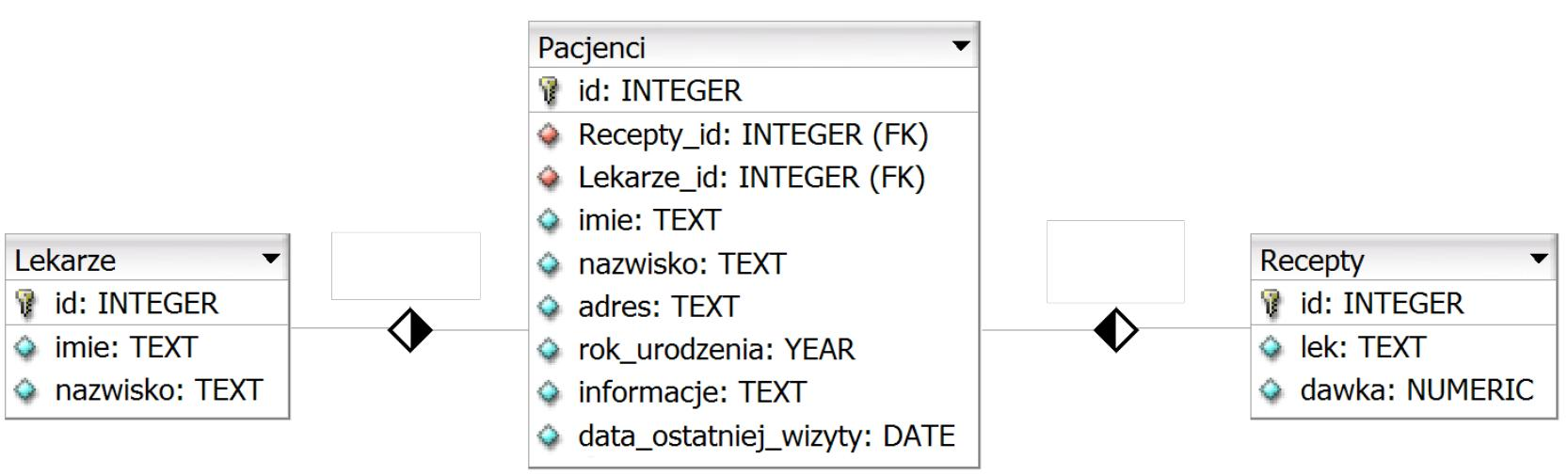
Na tabeli Pracownicy, której wiersze zostały pokazane na obrazie, wykonano przedstawioną kwerendę SELECT. Które dane zostaną wybrane?
| id | imie | nazwisko | stanowisko |
|---|---|---|---|
| 1 | Anna | Kowalska | 1 |
| 2 | Monika | Nowak | 2 |
| 3 | Ewelina | Nowakowska | 2 |
| 4 | Anna | Przybylska | 3 |
| 5 | Maria | Kowal | 3 |
| 6 | Ewa | Nowacka | 4 |
A. Monika, Ewelina, Maria.
B. Tylko Maria.
C. Tylko Anna.
D. Anna, Maria, Ewa.
Gratulacje, udzielona odpowiedź jest prawidłowa! Wykonana kwerenda SQL 'SELECT imie FROM pracownicy WHERE nazwisko = 'Kowal' OR stanowisko > 2;' zwraca imiona pracowników, którzy albo mają nazwisko 'Kowal', albo zajmują stanowisko o numerze większym niż 2. W kontekście przedstawionej tabeli pracowników, taka kwerenda zwróci nam poprawną odpowiedź 'Anna, Maria, Ewa'. To dlatego, że Anna pracuje na stanowisku 3, co jest większe niż 2, Maria ma nazwisko 'Kowal', a Ewa pracuje na stanowisku 4, które jest również większe niż 2. SQL jako język zapytań pozwala na efektywne zarządzanie danymi, niezależnie od skomplikowania zapytania. W praktyce, gdy mamy do czynienia z dużym zbiorem danych, takie zapytania pomagają w szybkim filtrowaniu i dostępie do potrzebnych informacji. Dobrym standardem jest wymyślanie i testowanie zapytań SQL w celu zrozumienia, jakie dane zostaną zwrócone, zanim zapytanie zostanie użyte w prawdziwej aplikacji lub systemie.