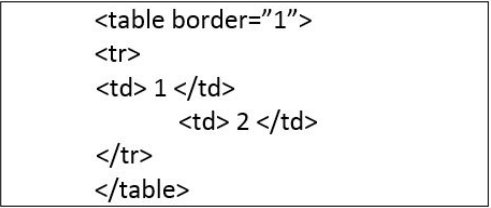
Pytanie 1
Na przedstawionej grafice znajduje się struktura sekcji dla witryny internetowej. Przyjmując, że blok5 nie ma przypisanej szerokości, a bloki są określone w dokumencie HTML w kolejności ich numeracji, jak powinno wyglądać zdefiniowanie opływania?
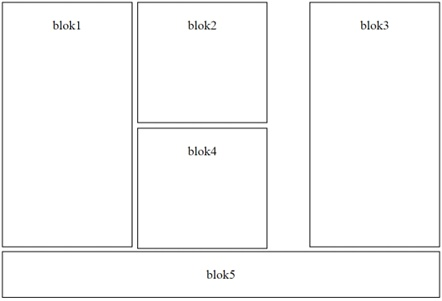
A. bloki 1, 2, 4 float: left; blok 3 float: right; blok 5 clear: both;
B. blok 1 float: left; bloki 2, 4 float: center; blok 3 float: right; blok 5 clear: both;
C. bloki 1, 2, 3, 4 float: right; blok 5 clear: right;
D. bloki 1, 2, 4 float: left; blok 3, 5 float: right;
Właściwe użycie float w CSS jest kluczowe do tworzenia układów stron. W pierwszej propozycji zastosowano float: left; dla bloków 1, 2, 4 oraz float: right; dla bloków 3 i 5, co jest niepoprawne, ponieważ blok 5 powinien być odseparowany od pozostałych poprzez clear: both;, aby zająć całą szerokość strony. W drugiej odpowiedzi, chociaż float: right; dla bloków 1, 2, 3, 4 może wydawać się poprawne dla niektórych stylów, blok 5 z clear: right; nie będzie działał, ponieważ nie uwzględnia float: left, które ma zastosowanie w układzie. Ostatnia odpowiedź używa float: center;, co jest nieprawidłowe, ponieważ w CSS nie istnieje taka właściwość. Elementy można centrować za pomocą innych metod, ale nie za pomocą float. Ponadto, przypisanie clear dla bloku 5 jest poprawne, ale pozostałe ustawienia float dla bloków są błędne i niezgodne z przedstawionym układem. Konsekwentne błędy często wynikają z braku zrozumienia, jak właściwości float i clear współdziałają w kontekście modelu pudełkowego w CSS.
 ```
```