Pytanie 1
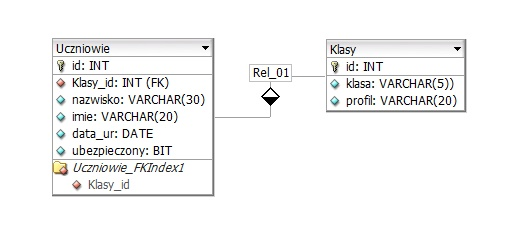
Podczas definiowania tabeli produkty należy stworzyć pole cena, które będzie reprezentować wartość produktu. Odpowiedni typ danych dla tego pola to
A. INTEGER(11)
B. TINYTEXT
C. ENUM
D. DECIMAL(10, 2)
Wybór typów danych dla pola przechowującego cenę produktu ma kluczowe znaczenie dla poprawności funkcjonowania bazy danych. INTEGER(11) jest typem, który przechowuje liczby całkowite, co oznacza, że nie może być zastosowany do reprezentacji wartości z miejscami dziesiętnymi, co jest niezbędne w przypadku cen. Użycie INTEGER może prowadzić do poważnych problemów, jak zaokrąglanie cen, co w branży handlowej może skutkować błędnymi transakcjami. TINYTEXT to typ danych przeznaczony do przechowywania tekstu, co czyni go całkowicie nieodpowiednim do reprezentacji wartości liczbowych, a tym bardziej cen. W przypadku zastosowania TINYTEXT w tym kontekście, nie tylko utracimy możliwość przeprowadzania obliczeń na cenach, ale również stworzymy dodatkowe problemy z wydajnością bazy danych, ponieważ operacje na tekstach są znacznie wolniejsze niż na liczbach. Z kolei ENUM, który jest używany do określenia zestawu dozwolonych wartości, nie ma zastosowania w kontekście cen, które mogą się zmieniać i nie są ograniczone do stałego zestawu opcji. Użycie ENUM do reprezentacji cen prowadziłoby do nieefektywności, ponieważ każda zmiana ceny wymagałaby modyfikacji definicji pola. Typowe błędy myślowe prowadzące do takich niepoprawnych wniosków to brak zrozumienia znaczenia precyzyjnego przechowywania danych finansowych oraz nieznajomość dostępnych typów danych i ich zastosowań w kontekście konkretnej aplikacji.