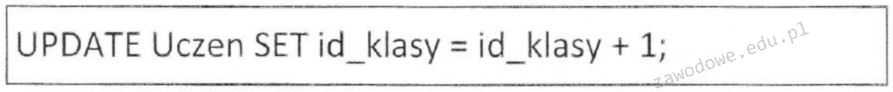Pytanie 1
Który z zaprezentowanych kodów HTML sformatuje tekst zgodnie z podanym wzorem? uwaga: słowo "stacji" jest napisane większą czcionką niż pozostałe wyrazy w tej linijce)
A. <p><small>Lokomotywa</small></p> <p>Stoi na <big>stacji<big> lokomotywa ...</p>
B. <h1>Lokomotywa</h1> <p>Stoi na <big>stacji</big> lokomotywa ...</p>
C. <h1>Lokomotywa</h1> <p>Stoi na <big>stacji</big> lokomotywa ...</p>
D. <h1>Lokomotywa</h1> <p>Stoi na <big>stacji lokomotywa ...</p>
Wybór innych opcji nie spełnia wymogów dotyczących odpowiedniego formatowania tekstu. W pierwszej opcji znacznik <big> otacza cały tekst 'stacji lokomotywa', co nie powoduje, że tylko 'stacja' jest większa, jak wymaga tego pytanie, co prowadzi do błędnej interpretacji wizualnej. W trzeciej opcji, użycie znaczników <h1> i <p> jest niepoprawne, ponieważ znacznik <h1> nie został zamknięty. Takie niedopatrzenie skutkuje błędami w renderowaniu i może wpływać na SEO, ponieważ nieprawidłowe użycie nagłówków może prowadzić do mylnych interpretacji przez wyszukiwarki. Czwarta opcja również wprowadza błędy, ponieważ <big> nie jest poprawnie zamknięte, co powoduje problemy z interpretacją przez przeglądarki. To pokazuje, jak ważne jest prawidłowe zamykanie znaczników oraz stosowanie semantycznie poprawnych znaczników HTML. W długim okresie może to prowadzić do trudności w utrzymaniu strony oraz problemów z jej dostępnością. Generalnie, nieprawidłowe użycie znaczników, niewłaściwa semantyka oraz brak zamykania znaczników prowadzą do błędów, które mogą być kosztowne w kontekście użytkowników i SEO.