Pytanie 1
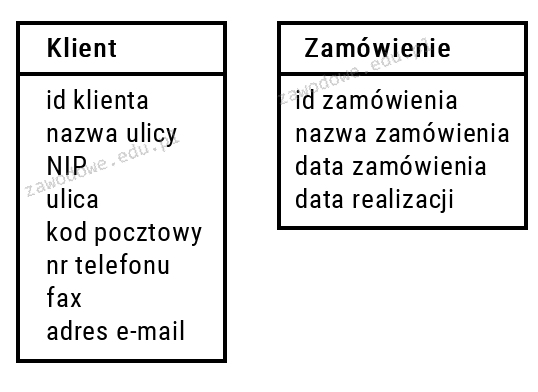
Jaką relację w projekcie bazy danych powinno się ustalić pomiędzy tabelami przedstawionymi na rysunku, przy założeniu, że każdy klient sklepu internetowego złoży co najmniej dwa zamówienia?
A. n:n
B. 1:n, gdzie 1 znajduje się po stronie Zamówienia, a wiele po stronie Klienta
C. 1:1
D. 1:n, gdzie 1 jest po stronie Klienta, a wiele po stronie Zamówienia
Relacja 1:n, gdzie 1 jest po stronie Klienta, a wiele po stronie Zamówienia, oznacza, że każdy klient może mieć wiele zamówień, ale każde zamówienie jest powiązane dokładnie z jednym klientem. To podejście odpowiada rzeczywistości większości sklepów internetowych, gdzie klienci wielokrotnie dokonują zamówień. Projektując bazę danych zgodnie z tą relacją, stosujemy klucz obcy w tabeli Zamówienia, który odwołuje się do klucza głównego w tabeli Klient. Jest to zgodne z dobrymi praktykami w projektowaniu baz danych, które zalecają minimalizowanie redundancji i zapewnienie integralności danych. Praktyczne zastosowanie tego modelu umożliwia łatwe śledzenie historii zamówień klientów, co jest kluczowe dla analizy sprzedaży i zarządzania relacjami z klientami. Relacja 1:n jest jedną z najczęściej stosowanych w modelowaniu danych, co potwierdza jej uniwersalność i skuteczność w różnych systemach informatycznych, od sklepów internetowych po systemy zarządzania zasobami ludzkimi.