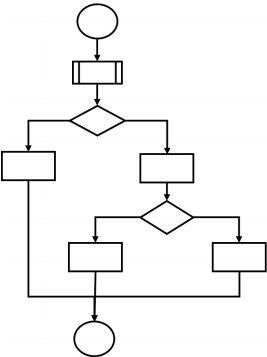
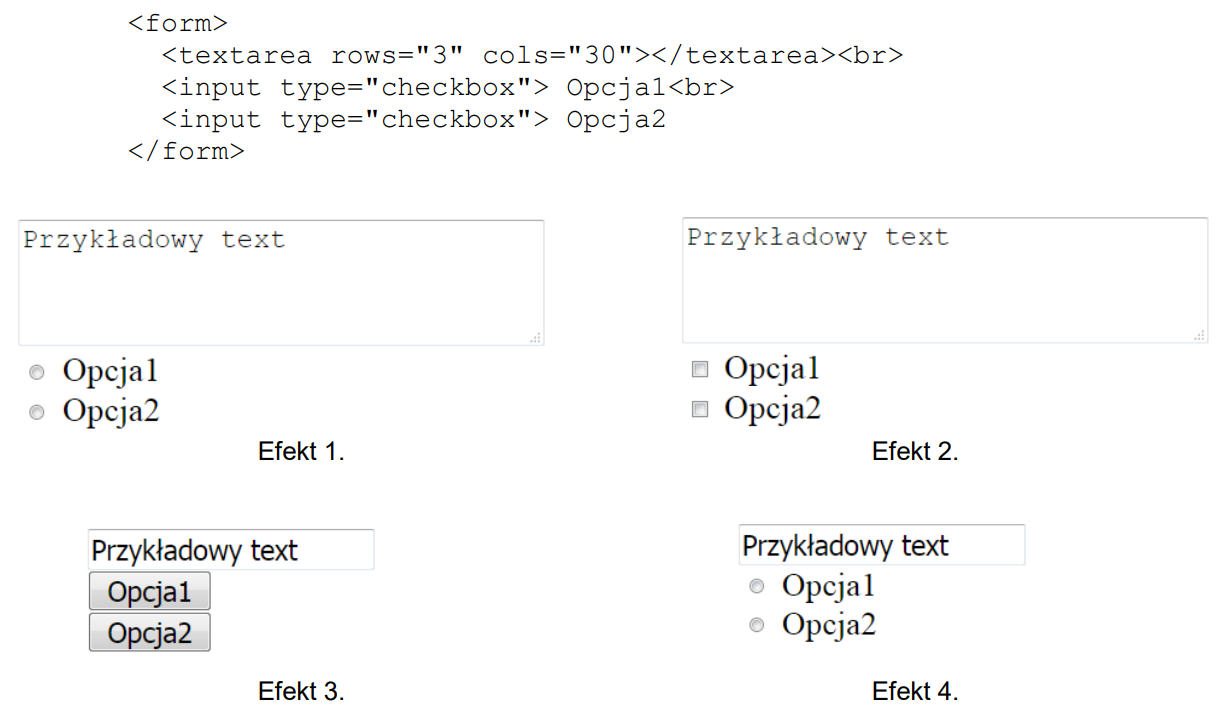
Pytanie 1
Które zdarzenie języka JavaScript jest wyzwalane w momencie, gdy kursor myszy znajduje się na elemencie do którego jest przypisane?
A. onmousedown
B. onmouseover
C. onmouseout
D. onmouseup
Prawidłowa odpowiedź to onmouseover, bo właśnie to zdarzenie w JavaScript uruchamia się w momencie, kiedy kursor myszy *wchodzi* na dany element i znajduje się nad nim. Przeglądarka monitoruje położenie kursora i gdy tylko „najedziesz” na element z przypisanym zdarzeniem onmouseover, wywoływany jest podpięty handler, na przykład funkcja w JavaScript. W praktyce często używa się tego do tworzenia efektów typu podświetlanie przycisków, rozwijane menu, podpowiedzi (tooltips) albo lekkie animacje po najechaniu. Przykładowo: `<button onmouseover="this.style.backgroundColor='orange'">Najedź na mnie</button>` – w chwili najechania myszką kolor tła przycisku się zmienia. Moim zdaniem to jedno z bardziej podstawowych zdarzeń, które warto ogarnąć na początku nauki frontendu, bo pozwala szybko zrobić stronę bardziej „żywą”. W nowoczesnym kodzie raczej unika się pisania atrybutów typu onmouseover bezpośrednio w HTML i zamiast tego stosuje się `addEventListener("mouseover", handler)` w JavaScript. Jest to zgodne z dobrymi praktykami i oddziela logikę od struktury dokumentu. Warto też wiedzieć, że onmouseover różni się od onmouseenter: onmouseover propaguje się (bąbelkuje) w górę drzewa DOM, co ma znaczenie przy bardziej złożonych interfejsach. Standardowe API DOM dokładnie opisuje te różnice i przy projektowaniu interakcji dobrze jest świadomie wybierać odpowiedni typ zdarzenia. W typowych projektach webowych onmouseover jest używany głównie do prostych reakcji na najechanie, ale trzeba pamiętać, by nie przesadzać z efektami, żeby nie przeciążyć użytkownika i nie zepsuć użyteczności strony.