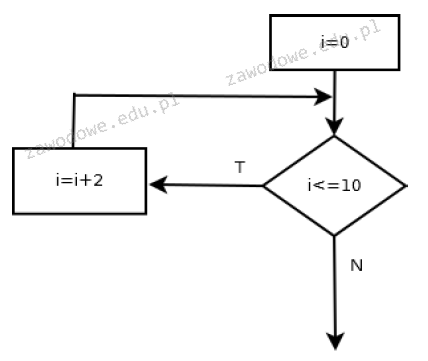
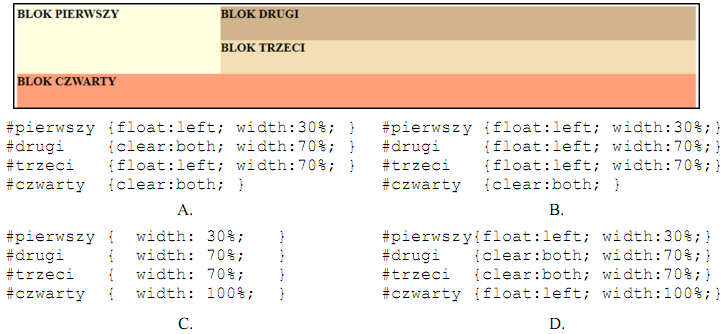
Pytanie 1
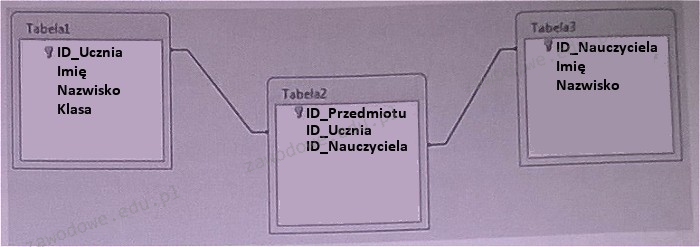
Określ rodzaj powiązania pomiędzy tabelami: Tabela1 oraz Tabela3
A. Wiele do wielu
B. Jeden do jednego
C. Jeden do wielu
D. Wiele do jednego
Zrozumienie typów relacji w bazach danych jest kluczowym aspektem projektowania efektywnych i zrównoważonych systemów informatycznych. Jednym z najczęstszych błędów jest mylenie relacji wiele do wielu z innymi rodzajami relacji, takimi jak jeden do wielu lub jeden do jednego. Relacja jeden do wielu oznacza, że jeden rekord w jednej tabeli jest powiązany z wieloma rekordami w innej tabeli, co w przypadku Tabela1 i Tabela3 nie jest stosowne, ponieważ wymagałoby to bezpośredniego połączenia między tymi tabelami bez użycia tabeli pośredniej. Z kolei relacja jeden do jednego implikuje, że każdy rekord w jednej tabeli odpowiada dokładnie jednemu rekordowi w drugiej tabeli, co ogranicza elastyczność danych i nie pasuje do struktur gdzie występuje wiele powiązań, jak w przypadku szkół, gdzie wielu uczniów może mieć zajęcia z tym samym nauczycielem. Wreszcie, relacja wiele do jednego jest odwrotnością relacji jeden do wielu, gdzie wiele rekordów w jednej tabeli odpowiada jednemu rekordowi w drugiej tabeli, co również nie znajduje odzwierciedlenia w przedstawionym schemacie, jako że nie opisuje wzajemnych powiązań uczniów i nauczycieli. Zrozumienie i prawidłowe zastosowanie relacji wiele do wielu eliminuje redundancję danych i umożliwia efektywne przechowywanie oraz przetwarzanie informacji w systemach zarządzania bazami danych. Kluczem do sukcesu jest tutaj wykorzystanie tabel pośrednich do prawidłowego mapowania powiązań między tabelami, co jest standardem w dobrych praktykach projektowania baz danych.